I'm relatively new to 3D printing, so I don't have an intuitive understanding of what to expect from various materials. I'm going to start documenting the various materials each time I try a new one. Unfortunately, my testing methodology won't be all that rigorous: I'm not an aerospace engineer, noone depends on my parts working under extreme conditions, and if you want rigorous testing you should probably be looking at Stefan from CNCKitchen's excellent work. In any case, I'll be keeping written records of what I did, and I'll be continually publishing the slicer profiles I use for printing on the Prusa i3 with each material.
I print almost entirely functional prints, so I care far more about the durability and dimensional accuracy of prints than I do about pretty looking surfaces and fine detail. I don't particularly care about determining exact MPa values for materials, I really just want to know if I'm likely to be able to break an object in normal usage. I also care about print times, and typically print at 0.3mm layer heights. I'm looking at transitioning to a Mosquito hotend with a larger nozzle so that I can blast out plastic at a higher rate, but currently I'm printing with the stock E3D v6 hotend and a 0.4mm nozzle. I've tried larger nozzles with this hotend, but have had issues with under-extrusion at higher print speeds likely due to exceeding the maximum volumetric speed for the hotend.
My intensely informal test approach is as follows:
First, I print a temperature tower to determine the usable temperature range for printing for the material.
Assuming that the temperature tower indicates that the material can be printed at all, a simple 80x15x15mm test rod is printed for durability tests. The test rod is printed with 15% cubic infill, at 0.3mm layer height, using whatever settings are recommended by the filament producer.
The test rod is checked for dimensional accuracy using digital calipers.
An attempt is made to crush the test rod by hand with pliers. The force is applied perpendicular to the plane of the print layers:
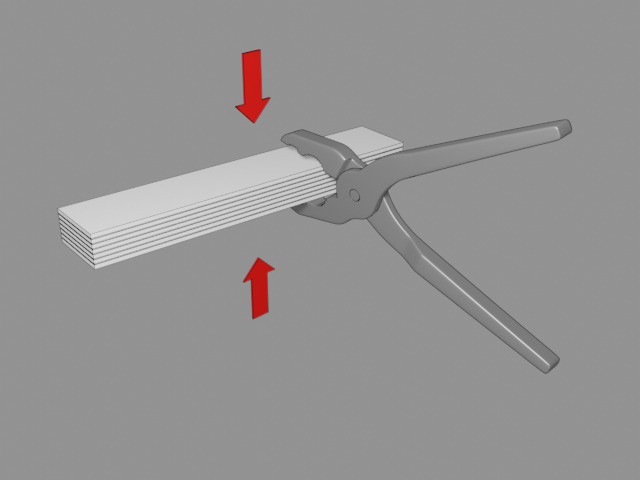
The purpose of this test is to determine if the actual material is "strong enough" with regards to withstanding crushing load.
Then, an attempt is made to crush the test rod by hand with pliers. The force is applied parallel to the plane of the print layers:

The purpose of this test is to determine if the material's layer adhesion is "strong enough".
Assuming that the test rod survives the pliers, I then try throwing the rod from head height as hard as possible onto a concrete floor a few times. This gives a rough indication as to whether or not the material and print are impact resistant in any sense.
As a reference, I printed a test rod using Prusa PLA. The rod was dimensionally accurate to within the accuracy of the nozzle (0.4mm), and survived the pliers test in both directions. The material did dent and crack slightly when thrown onto concrete, and this is supposedly to be expected for PLA (strong but brittle). Generally, if I'm going to be printing with a trickier material such as PETG or ABS, I expect to end up with a tougher result than this reference rod - otherwise what's the point?
First on the list: I recently ordered and received some Eryone PETG.
The box was good quality rigid cardboard, and the filament spool was vacuum-sealed in a bag with silica gel. The filament winding was precise, and tangle-free.

The spool after a dozen or so prints:

The temperature tower came out well. The bottom floor of the tower is 220°C and proceeds by 5°C per floor to reach 260°C at the top. Stringing wasn't visible until 230°C and still wasn't unusably severe at 260°C. There was a single bridging failure at 240°C, and a slightly more severe bridging failure at 260°C. The camera really brings out the printing flaws; they're not nearly as visible to the naked eye, and the finish is pretty uniformly glossy.

When it came to part strength, the material turned out to be fairly picky. I ended up having to print six different test rods to find a print profile that produced a strong part. I actually cracked the temperature tower at the start of the 245°C floor without intending to! The crack occurred mostly parallel to the layer lines, but crossed three or four layers in a step pattern.
After much trial and error, I ended up with the following settings:
Ambient temperature: 50°C Nozzle type: Brass 0.4mm Layer height: 0.3mm Print base: Smooth PEI sheet with glue stick Very slow print rate: bridge_speed = 25 external_perimeter_speed = 25 first_layer_speed = 20 gap_fill_speed = 25 infill_speed = 25 max_print_speed = 25 max_print_speed = 25 max_volumetric_speed = 0 perimeter_speed = 25 small_perimeter_speed = 25 solid_infill_speed = 25 support_material_interface_speed = 100% support_material_speed = 25 top_solid_infill_speed = 25 travel_speed = 180 Infill overlap: 55% Infill: 15% cubic Extruder Temperature: 230°C first layer, 235°C rest Bed Temperature: 85°C first layer, 90°C rest Perimeters: 3 Fans: 25%
I had trouble removing the first print from the PEI sheet, so moved to using a glue stick as a release agent for all subsequent prints. I'd strongly recommend using a glue stick for this material if you use a smooth PEI sheet and actually want to be able to remove your prints from the sheet afterwards!
I was able to crush all of the test rods using pliers except for PETG 4 which was produced using the above settings. For the PETG 4 rod, I could barely even produce a dent in the material! I've since printed other objects using the same settings but with fans entirely disabled with similar good results. It seems that this material has poor layer adhesion at low temperatures and/or with fans above 25%, and becomes pretty brittle.

Oddly, at 240°C, the material evidently started to bubble where it was in contact with the print bed:

The dimensional accuracy was fine. The test rod that wasn't destroyed measured
80.01mm × 14.99mm × 15.01mm, which is pretty close to perfect.
I printed two 3D benchy models at 0.3mm layer height, 40°C ambient temperature using the above settings, one with fans switched off, and one with fans fixed at 15% except for the first three layers. The one printed without fans looked a little deformed, with overhangs suffering somewhat, and overall looking a bit like someone had partially digested it. The one printed with fans had a more consistent shape, but suffered from layer adhesion issues.


The layer adhesion issues on the model printed with fans were severe enough that I could rip the model apart with my bare hands:

As far as I can make out, this material likes to be printed hot and in a hot environment. Quite frankly, I can't make an objective judgement about the quality of this particular brand of filament because I don't have anything else to compare it to yet. I suspect, given the consistent printing environment, high quality printer, reliable ambient temperature, and sensible print settings, I should probably be getting better results than this.
Continued in Part 2...
For 3D printing, I want to print with more challenging materials than the standard PLA filament. Materials such as PETG benefit from the increased ambient temperature afforded by a enclosing a 3D printer in some sort of box, and materials such as ABS practically require it in order to prevent temperature-induced warping of objects during printing.
I wanted to build an enclosure myself, but unfortunately doing so would have really required printing parts in ABS for durability and temperature resistance. This introduced a bootstrapping problem; I'd need an enclosure to print the parts I'd need to build an enclosure. Rather than deal with the problem, I decided to just throw money at it instead.
I looked at the available enclosure kits, and Tukkari seemed to be the best option for the price. I wanted to buy the enclosure that supported the Prusa MMU2 as I'm intending to upgrade at a later date. Unfortunately, at the time that enclosure was out of stock. I emailed Tukkari to ask when the enclosure was coming back in stock, and it turned out that they were due in a few days. I kept an eye on the Tukkari web site but didn't see any change in the "in stock" status. I was about to give up and go elsewhere, but then I received an email from Jan Khynych at Tukkari mentioning that they'd had higher than usual demand for the enclosure, but that they'd kept one back for me in reserve! I was really impressed by this; they knew they would have sold them anyway, but they courteously kept one back for me in case I wanted it. Needless to say, I said yes, and the kit arrived by courier less than a week later.
The assembly process was easy. It arrived as a well-packaged flat pack. The first step was to attach the rubber feet and various pegs to the wooden base:




Apparently it's a kind of tradition to include regional sweets with these kits. The Prusa i3 kit included gummy bears.
The next step involved fitting the back board to the base, and installing the air filter. The air filter is a combined carbon filter and HEPA filter. This should make it more pleasant to be near the printer when printing with a material like ABS that produces styrene gas and particulate matter when melted. I'm intending to fit ducting to the back of the enclosure to vent that stuff out of the room.



The door to the enclosure has a nice magnetic latch:

There's also a vent for the PSU:

I went with the spool holders that are designed to hold 2kg spools. I managed to screw this up, as I'll show later.

The final result:

So what I do think of the enclosure?
The good: The assembly was very easy. The packaging was excellent, with each individual piece of acrylic being packed in a protective film, and all parts protected from each other with polystyrene packing. The parts slot together very precisely, and the assembled enclosure feels rigid and sturdy. They included extra parts to fit a 120mm fan to the enclosure, and this allows for a slight negative air pressure inside the enclosure (which apparently is beneficial for reasons I don't fully understand) and also assists in getting ABS fumes out and away. The enclosure works as designed, and keeps a consistent ambient temperature during printing. I've not yet printed any ABS in it, but I've printed both PLA and PETG in it and have been unable to smell anything during prints. The PSU vent assists with keeping the PSU cool (the PSU is rated to operate in lower temperatures than the other electronic parts on the Prusa). I'd personally rather move the PSU outside of the enclosure entirely, but I can understand Tukkari not providing this as an option (it requires new cables for the printer).
The neutral: I mentioned earlier that I screwed up the spool holders. What happened was that I failed to tighten one of the bolts on the spool holders, and during the first test print inside the enclosure, the filament spool worked itself into a gap between the bearings and the acrylic piece and got wedged in place. This meant that the printer could no longer pull filament from the spool, so the filament sat inside the extruder slowly melting. This ultimately resulted in a jam, which I further exacerbated by turning the printer off at the wall. This had the effect of cutting cooling to the extruder heatsink (because the fans switched off), and melting the filament inside the extruder to produce a nice immovable blob. I ended up having to disassemble the extruder to fix the jam...


Note that this is not the fault of the enclosure: I didn't assemble the filament spool holder correctly, and paid for my mistake. There was no damage to the printer or extruder. I'm not too fond of the spool holder design though. The other spool holder that Tukkari offer is fixed-width rather than being two pieces that can move independently. I think their fixed-width design is better and I probably should have chosen that one.
I have been warned against printing with PLA filament inside the enclosure; the higher ambient temperature can cause the temperature inside the extruder to exceed the glass transition point of PLA, and can cause the filament to melt before it enters the tube. Picture someone jamming bubble gum into a series of cogs, and you have a pretty accurate illustration of what can happen.
The bad: My criticism of the enclosure is really more philosophical than anything. The enclosure is presumably intended to be sold to DIY-level users rather than industrial-level users. People who are using DIY-level printers are very much the kind of people who are going to be endlessly modifying their printers and, by extension, their enclosures. The enclosure doesn't really offer any way to attach extra parts without actually permanently modifying the enclosure by drilling holes in it. Drilling holes in acrylic can be fraught with danger; it's pretty easy to crack acrylic and, once it cracks, it's more or less impossible to stop it cracking further. There are no threads on the sides of the enclosure where one could bolt a camera or lighting to help supervise prints. If you want to place the Prusa LCD outside of the enclosure, your only real option is to place it on top of the enclosure, and you need longer ribbon cables to do that (the cables supplied with the Prusa are just long enough to reach the front of the printer frame, and that's it). I'd like to see more options for extensibility in future revisions of this enclosure. I'm aware that there's a tension between adding extra holes and the like for extension, and keeping it actually functioning as an enclosure!
For now, I think I'm going to try to print off some brackets that I can bolt to the top of the enclosure (where the bolts pass through the top acrylic piece into the side acrylic pieces). This should hopefully allow me to bolt other things to the brackets such as the Raspberry Pi I currently have placed haphazardly on a box in front of the enclosure, and a separate USB webcam on a poseable arm. I've since replaced the provided spool holders with a dry box that sits on top of the enclosure.
Overall: The enclosure is pretty good. I'll be using it for the forseeable future!
Recently decided to start learning about 3D printing. Ordered a Prusa i3 MK3S kit a few weeks ago, and it arrived a couple of days ago. The packaging and documentation was excellent, and the print results essentially flawless.

The first step was to assemble the X and Y axes. This basically consisted of bolting together aluminium frame pieces. Care had to be taken to ensure that everything was aligned correctly and that the frame didn't wobble when placed on a flat surface.

Next, the heated bed carriage had to be attached to rods:

Next, the belt had to be connected to the motor that drives the heated bed carriage:

The Z axis motors were then connected to the frame along with the threaded rods that are used to move the extruder on the Z axis:

Assembling the extruder took the best part of a day. I took excessive care to heed all of the warnings given in the documentation...




The extruder then had to be mounted, and the various cables inserted into a textile sleeve in order to keep them out of the way during printing:





The LCD panel was mounted on the front of the frame:

This was then followed by the heatbed and 24v power supply:



It was then necessary to attach the microcontroller, and attach all of the motors and other cables to it. This was easy enough, and the documentation went into a lot of detail on how to manage the cables in a sane way.




The last step was to attach the filament spool holder.

After calibration, the initial PRUSA logo and Pug test print gave good results:




Gave a presentation at the Sonatype User
Conference
back on 2020-08-12 on how the Library
Simplified project uses
Maven Central and the principles of
modularity to develop
and deliver Android components.
