It's that time of year again.
Fingerprint | Comment --------------------------------------------------------------------------- A438 A737 C771 7871 95CF C166 F843 51F7 2C91 8476 | 2023 personal 62AB 091D 563E 51BE 9E54 B680 7E20 DC73 5505 FE84 | 2023 maven-rsa-key 567B 7EA4 703E D530 5B73 3FBC 10C3 9A85 438F 996F | 2023 jenkins-maven-rsa-key
Keys are published to the keyservers as usual.
Did a pile of server updates today, and for some reason one specific VPS refused to boot with this error:
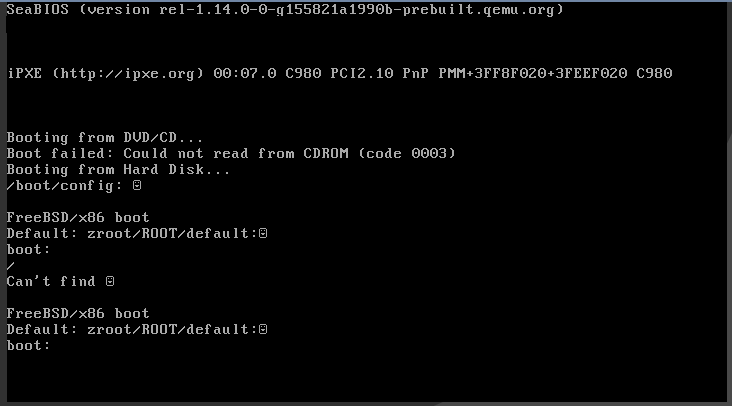
It turned out I hadn't updated the boot code to handle the latest zpool version. There's a note about this buried at the bottom of the zpool administration chapter of the FreeBSD documentation:
https://docs.freebsd.org/en/books/handbook/zfs/#zfs-zpool
This would be fine, except I've literally never had to do this once on any number of physical machines or virtual machines over more than a decade of continual upgrades. I don't understand why it was suddenly a problem on this one machine.
I mounted a FreeBSD ISO into the virtual machine, booted from it, temporarily
imported and mounted the zroot zpool to /mnt and ran:
# gpart bootcode -b /boot/pmbr -p /boot/gptzfsboot -i 1 vtbd0
Exported the zpool again, and rebooted. Machine came up.
It's that time of year again.
Fingerprint | Comment --------------------------------------------------------------------------- 2680 A50E FD03 2007 FABE 8C87 B0E4 322E EE81 8BDE | 2022 personal 3CCE 5942 8B30 462D 1045 9909 C560 7DA1 46E1 28B8 | 2022 maven-rsa-key 8EAE 10EA 3E8D F42F E58F CFD2 7863 6912 E065 EAD3 | 2021 jenkins-maven-rsa-key
Keys are published to the keyservers as usual.
I'm attempting to print a part like this:

The part must be printed in the orientation shown due to the anisotropic properties of 3D printed parts: The part needs to be printed such that the print layers are oriented perpendicular to the expected load.
This wouldn't normally be an issue, but the part is 25cm long. The build volume of the Prusa i3 MK3S is 250 × 210 × 210 mm. That left me exactly one way to print the part: Lay it on the print bed lengthwise.
Because I wasn't completely certain that the part dimensions were correct, I printed a small slice of the end of the model for testing:

Unfortunately, the printed part was pretty severely warped. The two highlighted lines are supposed to be parallel!

The part was printed in eSun ABS. Now, ABS has the reputation of being difficult to print. It reportedly has a tendency to warp and shrink in exactly the manner shown above. However, my personal experience of ABS has been the complete opposite to date! I've not, so far, had a single part warp in any observable way. I think I've had good results so far due to printing exclusively in an enclosure, using a 110°C heated bed, and tuning the material settings carefully. Therefore, having a part come out of the enclosure looking like this was a bit of a surprise.
My first thought was to question where I was printing on the bed. I don't normally print in that lower right corner. I tried moving the slice of the model to the middle of the print bed and printing again... No warping!
Late last year, I attached a small PVC duct to the back of the enclosure so that I could vent ABS fumes out of the window during prints. Given that we're coming into the winter months in the UK, I wondered if the warping was actually caused by a cold draft from outside getting into the enclosure and ruining the first print. I moved the part back into the corner and printed again... It warped. Not only did it warp, but it suspiciously warped in exactly the same manner as the first print; one of the corners (not both) lifted from the heat bed. Coincidentally, the corner that lifted was the corner that was placed in the same location on the heat bed both times (the bottom right corner).
I tried printing a version of the part with "mouse ears" - small brims placed under each corner. Once again, the part warped, and specifically only warped on one corner. The entire brim on that corner of the part actually lifted off the heat bed, whilst the other corner stayed firmly down.

In the above image, the marked lines are supposed to be parallel. Severe warping and buckling can be observed on the right side of the part, and absolutely no warping is present on the left side. The part is symmetrical; if it warped on one side, it should warp on the other.
At this point, I was pretty much convinced that something was unusual about that specific part of the heat bed.
I found a discussion thread on the Prusa forums where someone had produced a thermal image of the heat bed running at temperatures very close to the temperatures I'm using for ABS:
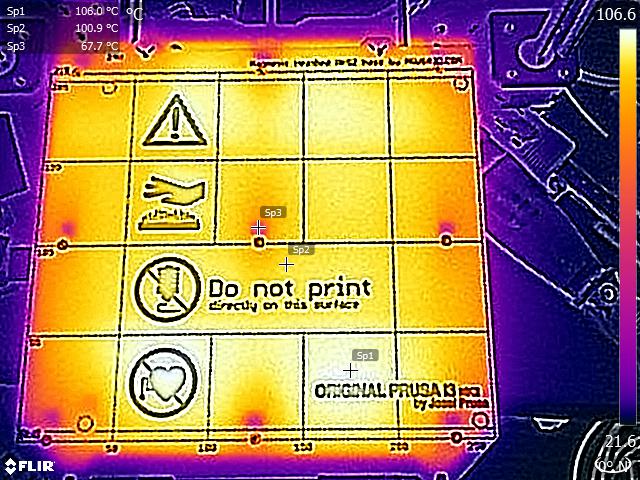
The original poster notes:
Heat distribution is not perfectly even, but it doesn't look too bad. The cold spots are where the magnets sit.
...
These images are without a steel sheet attached. When a steel sheet is added, it should spread out the heat more evenly towards the perimeters of the bed.
Note that in the image, both the bottom left and bottom right areas of the heat bed are noticeably colder than the rest. This might not matter for larger parts, but for a part with a small corner area, it clearly does!
I suspect moving the part to the next grid square over (in the horizontal band that says "Do not print") will fix the problem.
Installation
All of this is in the documentation, but here's a friendly version.
First, grab the changelog jar
file and wrapper script. At the time of writing the current version is 4.1.0.
You can get both from Maven Central:
Download them with wget:
$ wget https://repo1.maven.org/maven2/com/io7m/changelog/com.io7m.changelog.cmdline/4.1.0/com.io7m.changelog.cmdline-4.1.0-main.jar $ wget https://repo1.maven.org/maven2/com/io7m/changelog/com.io7m.changelog.cmdline/4.1.0/com.io7m.changelog.cmdline-4.1.0-main.jar.asc $ wget https://repo1.maven.org/maven2/com/io7m/changelog/com.io7m.changelog.cmdline/4.1.0/com.io7m.changelog.cmdline-4.1.0.sh $ wget https://repo1.maven.org/maven2/com/io7m/changelog/com.io7m.changelog.cmdline/4.1.0/com.io7m.changelog.cmdline-4.1.0.sh.asc
I recommend verifying the signatures, for security reasons. You can skip this step if you like to live dangerously.
$ gpg --verify com.io7m.changelog.cmdline-4.1.0-main.jar.asc gpg: assuming signed data in 'com.io7m.changelog.cmdline-4.1.0-main.jar' gpg: Signature made Tue 12 Jan 2021 20:11:22 GMT gpg: using RSA key B32FA649B1924235A6F57B993EBE3ED3C53AD511 gpg: issuer "contact@io7m.com" gpg: using pgp trust model gpg: Good signature from "io7m.com (2021 maven-rsa-key) <contact@io7m.com>" [full] Primary key fingerprint: B32F A649 B192 4235 A6F5 7B99 3EBE 3ED3 C53A D511 gpg: binary signature, digest algorithm SHA512, key algorithm rsa3072 $ gpg --verify com.io7m.changelog.cmdline-4.1.0.sh.asc gpg: assuming signed data in 'com.io7m.changelog.cmdline-4.1.0.sh' gpg: Signature made Tue 12 Jan 2021 20:11:22 GMT gpg: using RSA key B32FA649B1924235A6F57B993EBE3ED3C53AD511 gpg: issuer "contact@io7m.com" gpg: using pgp trust model gpg: Good signature from "io7m.com (2021 maven-rsa-key) <contact@io7m.com>" [full] Primary key fingerprint: B32F A649 B192 4235 A6F5 7B99 3EBE 3ED3 C53A D511 gpg: binary signature, digest algorithm SHA512, key algorithm rsa3072
You need Java 11 or newer installed. Check that you have an up-to-date version:
$ java -version openjdk version "15.0.2" 2021-01-19 OpenJDK Runtime Environment (build 15.0.2+7) OpenJDK 64-Bit Server VM (build 15.0.2+7, mixed mode)
Now, place both the jar file and the sh script somewhere on your $PATH.
Personally, I use a $HOME/bin directory for this sort of thing.
$ echo $PATH /usr/local/sbin:/usr/local/bin:/usr/bin:/usr/bin/site_perl:/usr/bin/vendor_perl:/usr/bin/core_perl:/home/rm/bin $ mkdir -p $HOME/bin $ mv com.io7m.changelog.cmdline-4.1.0-main.jar $HOME/bin/ $ mv com.io7m.changelog.cmdline-4.1.0.sh $HOME/bin/changelog $ chmod +x $HOME/bin/changelog $ which changelog /home/rm/bin/changelog
The changelog wrapper script requires two environment variables, CHANGELOG_HOME
and CHANGELOG_JAR_NAME, to be defined. This allows the wrapper script to
find the jar file and run it. The CHANGELOG_HOME environment variable
tells the wrapper which directory it needs to look into for the jar file,
and the CHANGELOG_JAR_NAME variable specifies the name of the jar file.
$ export CHANGELOG_HOME="$HOME/bin" $ export CHANGELOG_JAR_NAME="com.io7m.changelog.cmdline-4.1.0-main.jar"
Now, you should be able to run changelog:
$ changelog
changelog: Main: INFO: Usage: changelog [options] [command] [command options]
Options:
--verbose
Set the minimum logging verbosity level.
Default: info
Possible Values: [trace, debug, info, warn, error]
Use the "help" command to examine specific commands:
$ changelog help help.
Command-line arguments can be placed one per line into a file, and the file
can be referenced using the @ symbol:
$ echo help > file.txt
$ echo help >> file.txt
$ changelog @file.txt
Commands:
change-add Add a change to the current release.
help Show detailed help messages for commands.
initialize Initialize the changelog.
release-begin Start the development of a new release.
release-current Display the version number of the current release.
release-finish Finish a release.
release-set-version Set the version number of the current release.
version Retrieve the program version.
write-atom Generate an atom feed.
write-plain Generate a plain text log.
write-xhtml Generate an XHTML log.
Documentation:
https://www.io7m.com/software/changelog/documentation/
Usage
See the documentation
for information on how to use the various changelog subcommands.
Editing Manually
Given that changelogs are simple XML files, it's possible to manually edit
them in any text editor. However, the changelog tool is very strict about
the format of changelogs, and will summarily reject any changelog that isn't
valid according to the published XSD schema.
Modern IDEs such as Intellij IDEA contain excellent support for real-time XML editing, including autocompletion of XML elements, and real-time schema errors as you type. This makes it very difficult to accidentally create an invalid changelog file.
First, download the schema file and save it somewhere. For this example,
I saved it in /tmp/schema.xsd, but you'll probably want to keep it somewhere
a little more permanent than your temporary directory!
$ wget https://raw.githubusercontent.com/io7m/changelog/develop/com.io7m.changelog.schema/src/main/resources/com/io7m/changelog/schema/schema.xsd $ mv schema.xsd /tmp
If you were to open an existing project that contained a README-CHANGES.xml
file that was created with the changelog tool at this point, you would see
something like this:
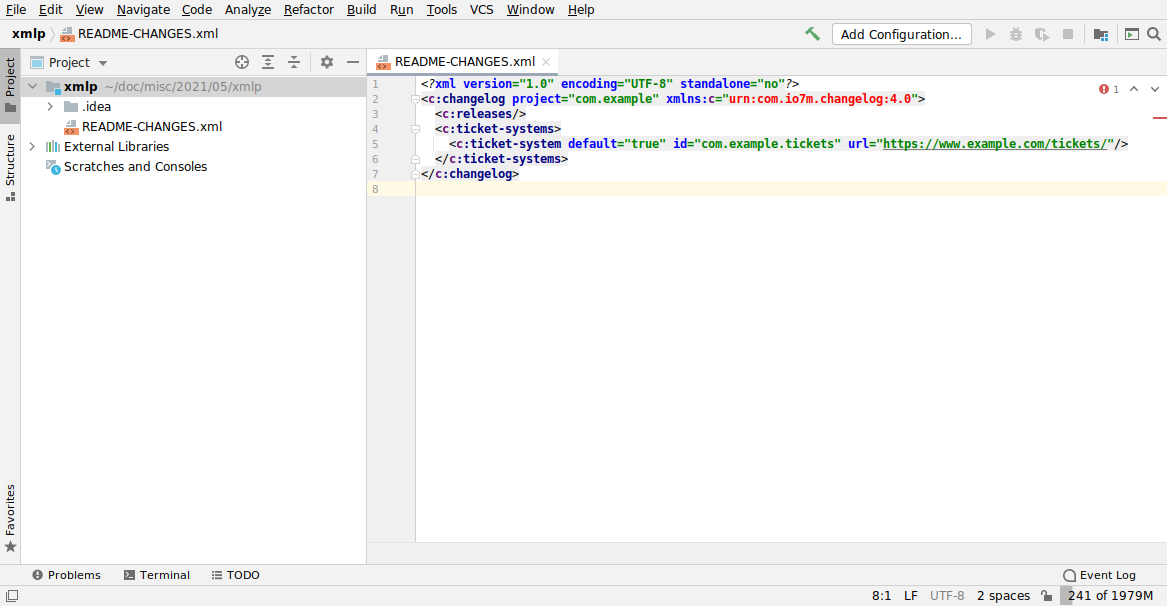
Note that the XML namespace is highlighted in red, because the IDE doesn't
know where to find the schema for that namespace. If you click the namespace
and then ALT+Enter, you'll get a drop-down menu that will allow you to set
up the schema file:
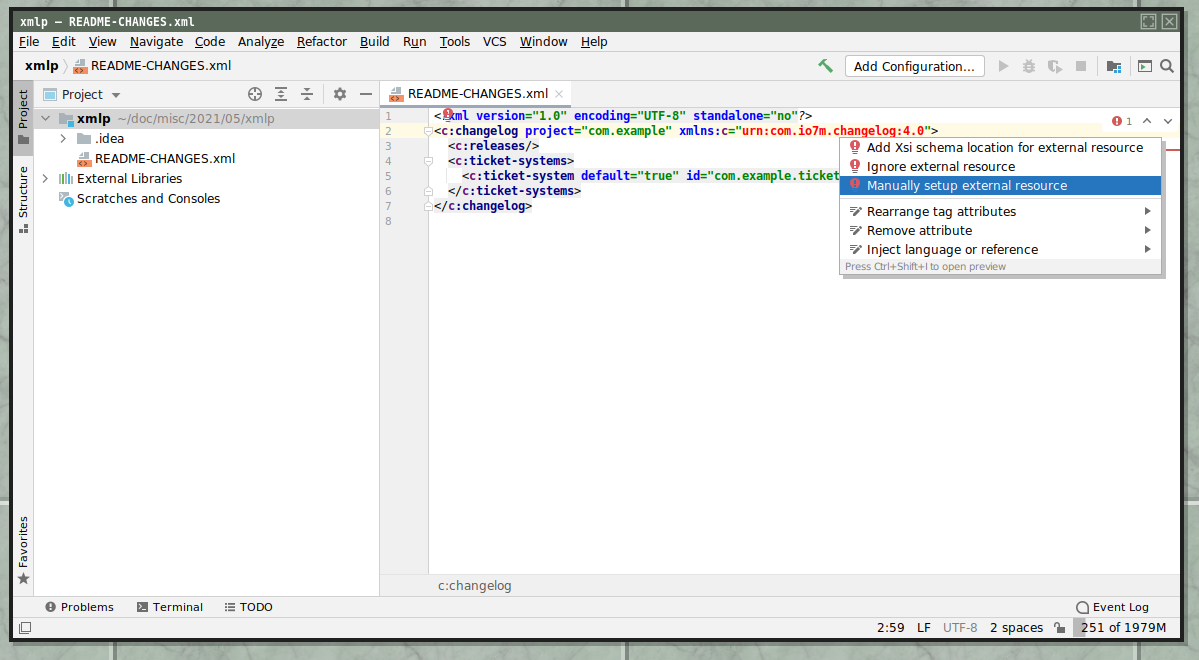
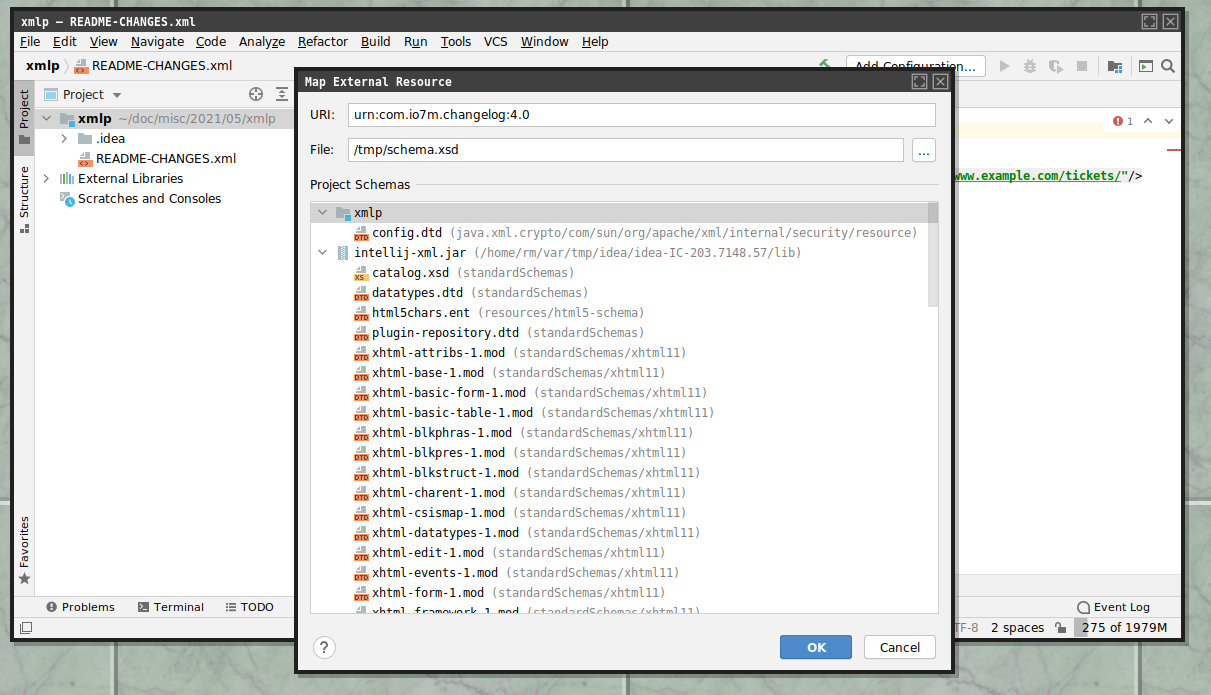
If you select "Manually setup external resource", you'll get a file picker
that you can use to select the schema.xsd file you downloaded earlier:
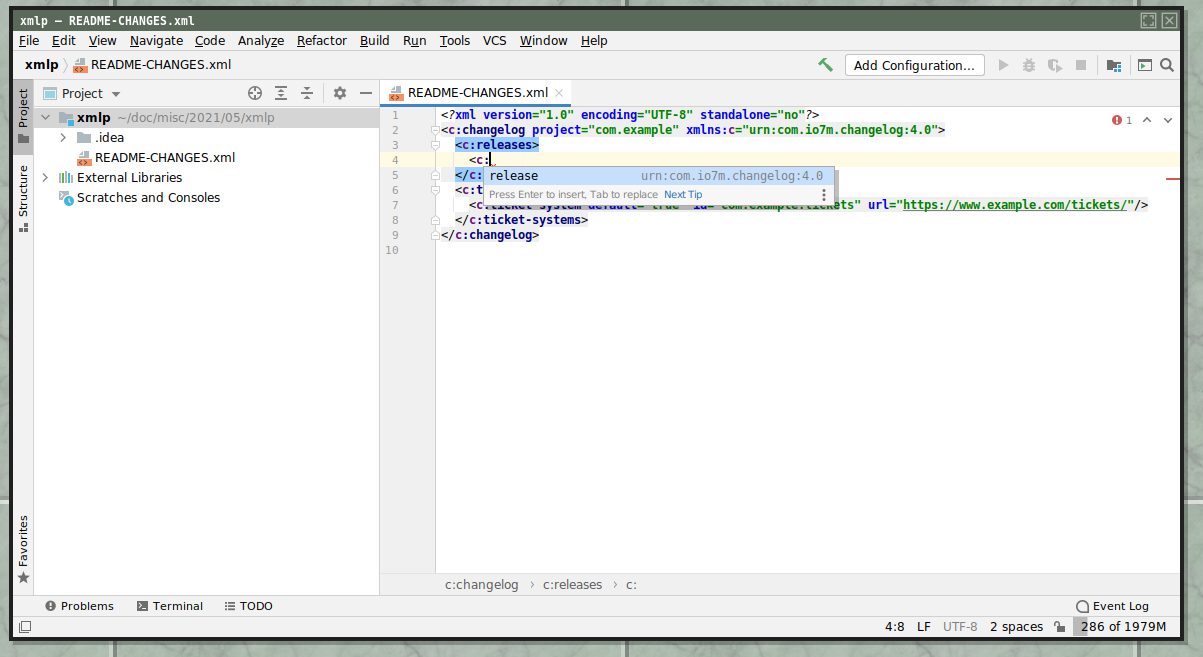
Now, when the schema file is selected, the XML namespace is no longer highlighted in red. Additionally, when you type, you'll be offered autocompletions of XML elements:
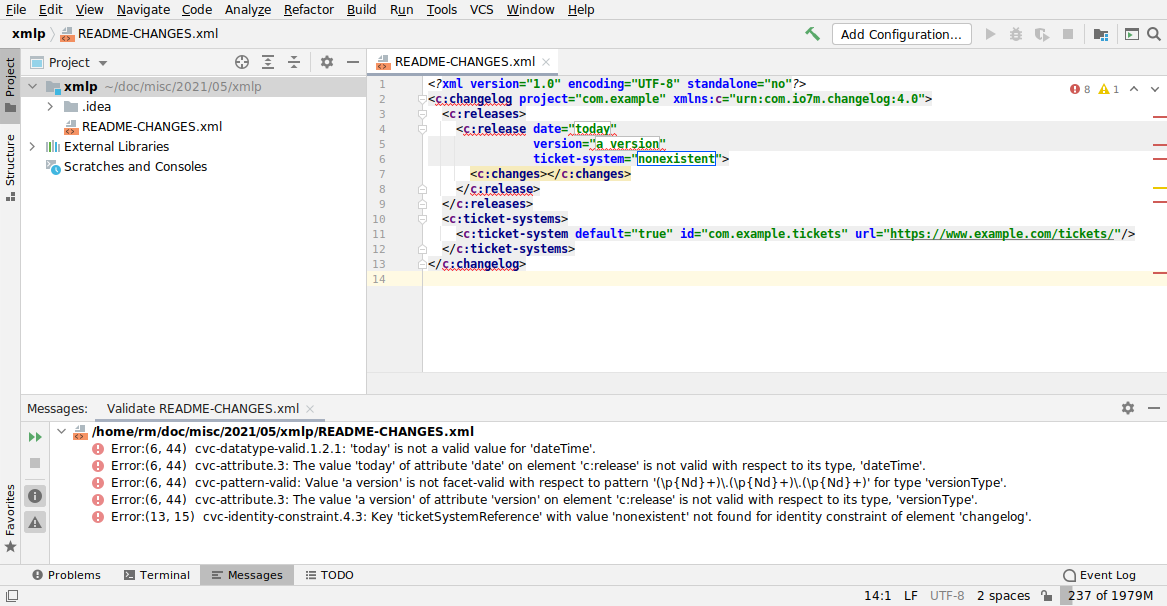
If you make mistakes editing the changelog file, you'll get nice validation errors as you type.
Here's "you tried to create an element that's not in the schema":
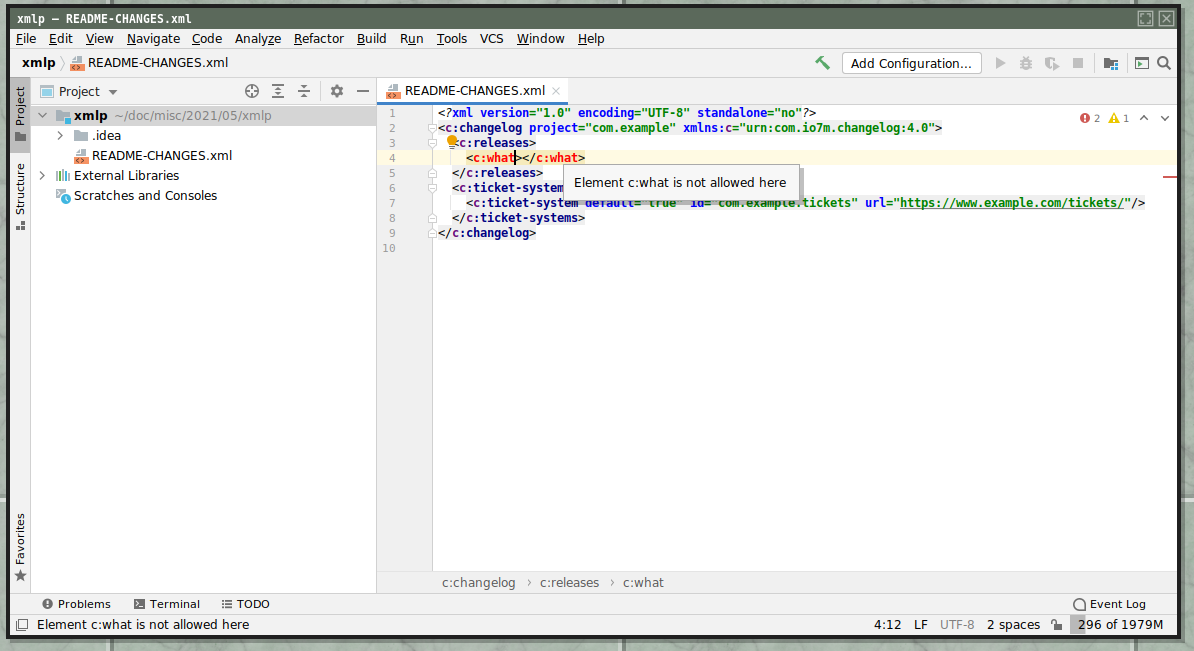
Here's "you typed garbage into the attributes of a known element":
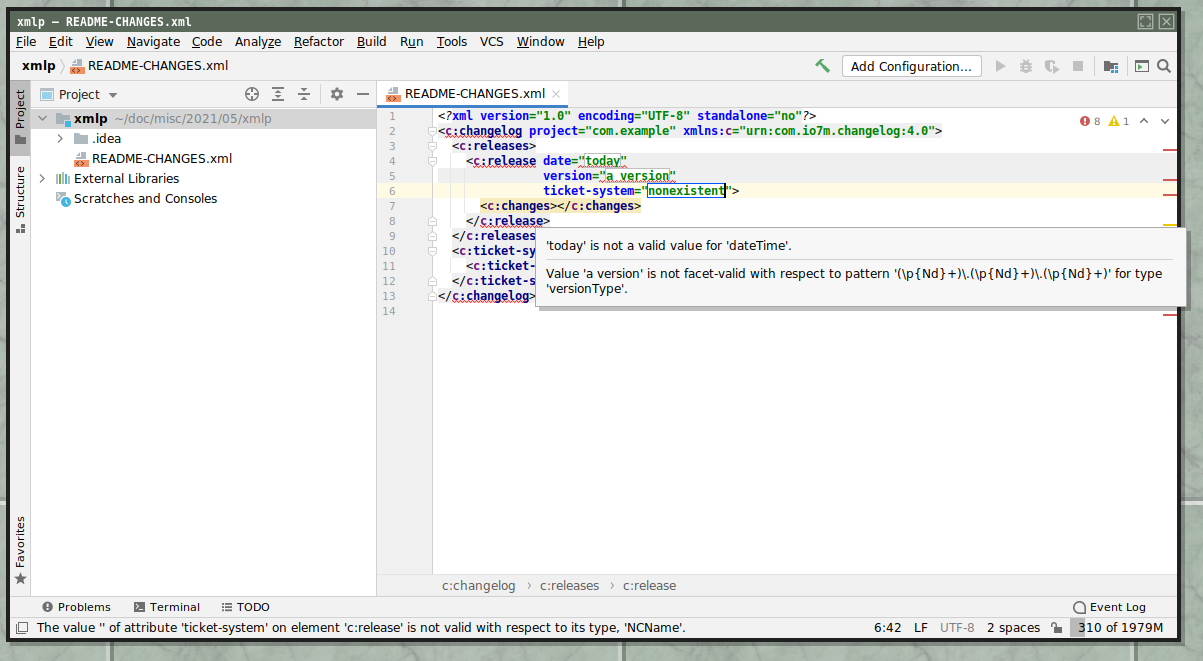
Here's "you tried to reference an undeclared ticket system":
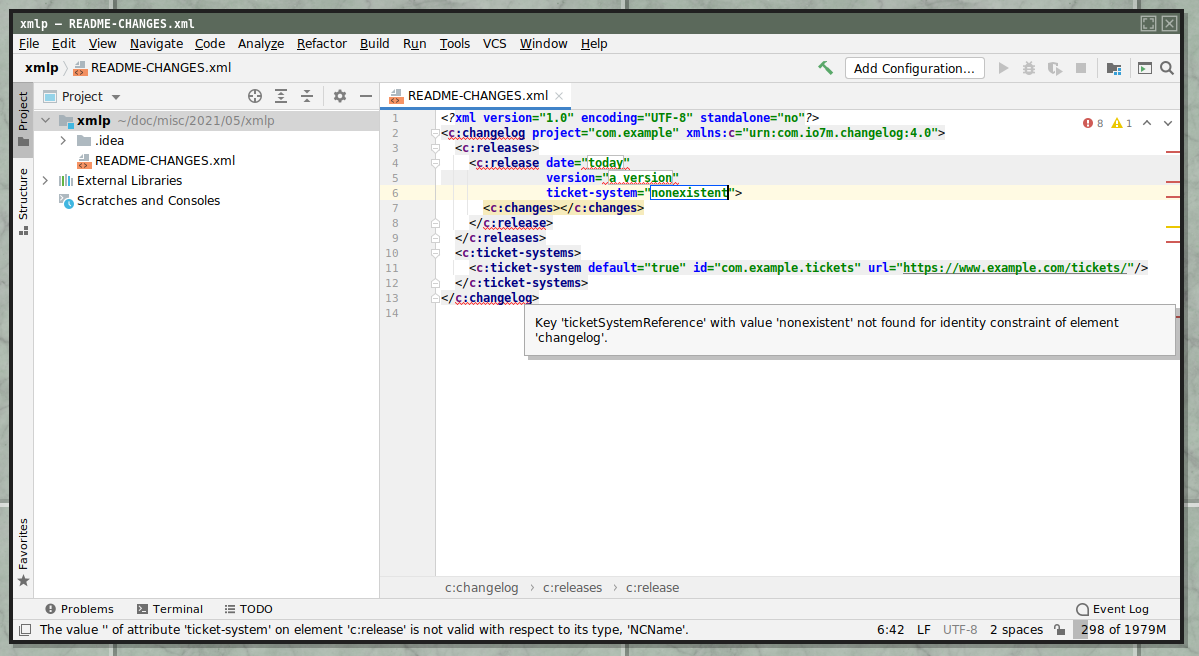
You can also, at any point, right-click the editor and select "Validate" to see the complete list of errors: