Been working intensely on the room model.
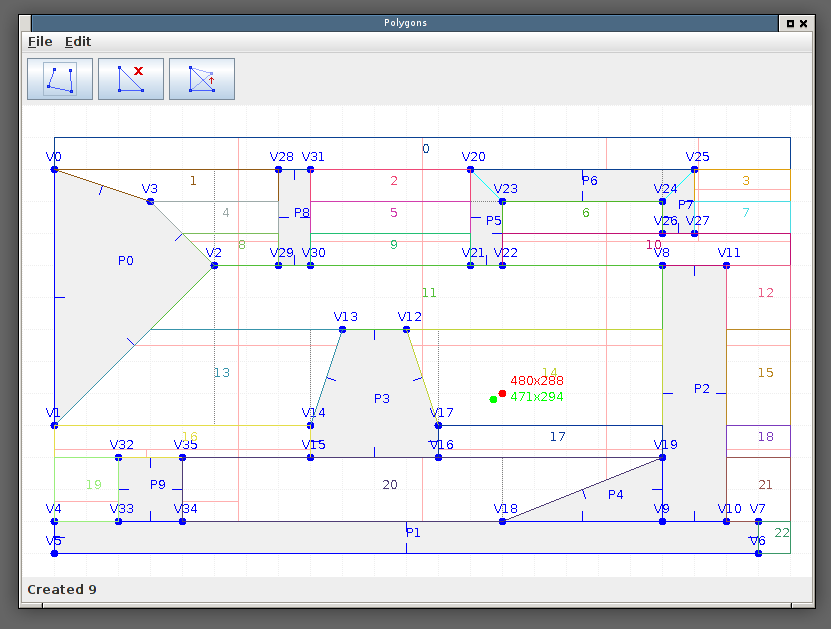
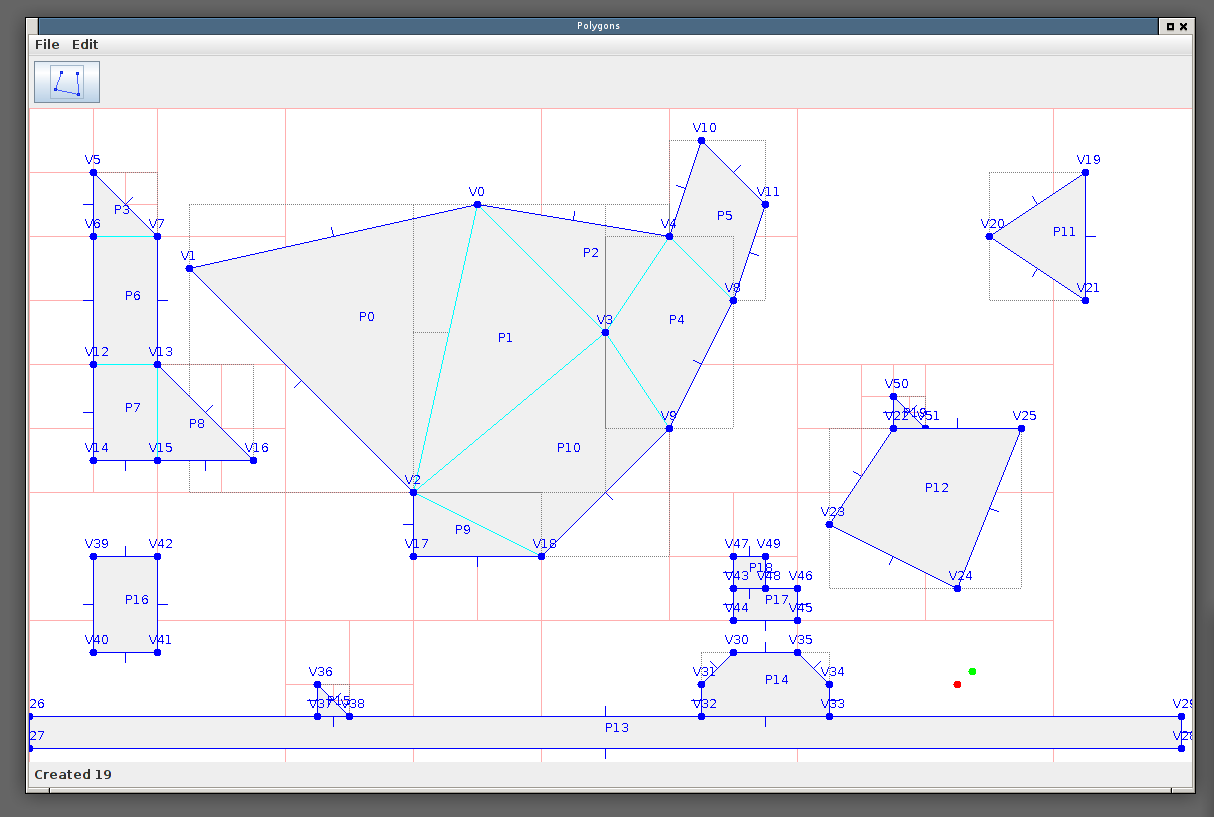
The intention here is to analyze a set of polygons and divide the space outside the polygons into horizontal spans. The horizontal spans represent areas within which water would pool if it was poured into the space. Actually producing these polygons with usable up/down connectivity information has turned out to be a surprisingly fiddly computational geometry problem! I've still not completely solved it.
Experimenting with a room model for the engine.
Made some corrections to zeptoblog to ensure that the output is valid XHTML 1.0 Strict. I bring this up because it directly affects this blog. I'm now validating the output of this blog against the XHTML 1.0 Strict XSD schema, so any problems of this type should be caught immediately in future.
I released version 1.0.0 of
jregions a while back and then
found that I wanted to make some changes to the API. I didn't want
to make a compatibility-breaking change this close to 1.0.0, so I
decided to make the changes but keep some deprecated compatibility
methods in place.
However, some of the types involved are generated by the
immutables package. The way the package works
is that you define an abstract interface
type and immutables generates an immutable implementation of
this interface. One of the parts of the generated implementation
is a builder type that allows you to construct instances of the
implementation type in multiple steps. For example, a declaration
like this:
@Value.Immutable
interface SizeType
{
int width();
int height();
}
... would result in the generation of an immutable Size class that
contained a mutable Size.Builder type capable of constructing values
of Size:
Size s = Size.builder().setWidth(640).setHeight(480).build();
In my case, I wanted to rename the width and height methods to
something more generic. Specifically, width should be sizeX and
height should be sizeY. Clearly, if I just renamed the methods
in the SizeType, then the generated type and the generated builder
type would both be source and binary incompatible. I could do this:
@Value.Immutable
interface SizeType
{
int sizeX();
int sizeY();
@Deprecated
default int width()
{
return sizeX();
}
@Deprecated
default int height()
{
return sizeY();
}
}
That would at least preserve source and binary compatibility for
the API of the generated type, but the generated builder type
would no longer have setWidth or setHeight methods, so
source and binary compatibility would be broken there. I asked
on the immutables.org issue tracker, and right away Eugene
Lukash stepped in with a nice
solution. Thanks
again Eugene!
Switch to the project directory, and:
$ find . -name '*.iml' -exec rm -v {} \;
$ rm -rfv .idea
Reopen the project and hope intensely.
