I've been working with Stable Diffusion lately.
One acknowledged "problem" with these kinds of text-to-image systems is that it's difficult to generate consistent subjects and/or background environments between images. Consider the case of a comic book artist using the system to create background images for each panel: If the characters are all standing in a room, then it's probably desirable for the room to look the same in each panel.
I've been working on a mostly-automated system for generating consistent scenes by combining an image-to-image workflow, 3D rendered images produced from Blender, and some scripting and techniques lifted from deferred rendering to produce a camera-dependent text prompt automatically.
Thinking Machines
Image generation systems like Stable Diffusion aren't intelligent. The system doesn't really understand what it's generating, and there's no way to tell it "give me the same room again but from a different camera angle". It has no concept of what a room is, or what a camera is.
It's somewhat difficult to describe processes in Stable Diffusion, because it's very tempting to talk about the system in terms of intelligence. We can talk about Stable Diffusion "improvising" objects and so on, but there's really nothing like human improvisation and cognition occurring. During generation, the system is taking manually-guided paths through a huge set of random numbers according to a huge, cleverly-constructed database of weight values. Nevertheless, for the sake of making this article readable, I'll talk about Stable Diffusion as if it's an intelligent system making choices, and how we can guide that system into making the choices we want.
In order to produce a consistent scene, it appears to be necessary to start with consistent source images, and to provide an accurate text prompt.
Requirements: Text Prompt
Stable Diffusion works with a text prompt. A text prompt describes the objects that should be generated in a scene. Without going into a ton of detail, the Stable Diffusion models were trained on a dataset called LAION-5b. The dataset consists of around 5.8 billion images, each of which were annotated with text describing the images. When you provide Stable Diffusion with a text prompt consisting of "A photograph of a ginger cat", it will sample from images in the original dataset that were annotated with photograph, ginger cat, and so on.
The generation process is incremental, and there appears to be a certain degree of feedback in the generation process; the system appears to inspect its own output during generation and will effectively try to "improvise" objects that it believes it might be generating if nothing in the text prompt appears to describe the random pile of pixels it is in the process of refining. More concretely, if the generation process starts producing something that looks orange and furry, and nothing in the prompt says ginger cat, then the system might produce an image of a dog with ginger hair. It might just as easily produce an image of a wicker basket!
It's therefore necessary, when trying to generate a consistent scene, to describe every important object visible in the scene in the text prompt. This requirement can lead to problems when trying to generate a scene from multiple different camera viewpoints in a room:
-
If an object
Ois visible in camera viewpointAbut not visible in camera viewpointB, and the artist forgets to remove the description ofOfrom the text prompt when generating an image fromB, Stable Diffusion might replace one of the other objects in the scene with an improvised version ofO, because it believes that the description ofOmatches something else that is visible inB. -
If an object
Ois visible in both camera viewpointAand camera viewpointB, and the artist forgets to include a description ofOin the prompt when generating an image fromB, thenOmight appear completely different inAandBbecause, lacking a description ofO, Stable Diffusion will essentially just improviseO.
Additionally, the way the text prompt works in Stable Diffusion is that text that appears earlier in the prompt is effectively treated as more significant when generating the image. It's therefore recommended that objects that are supposed to be more prominently displayed in the foreground be described first, and less significant objects in the background be described last.
We would therefore like to have a system that, for each visible object in the current camera viewpoint, a one-sentence textual description of the object is returned. If an object isn't visible, then no description is returned. The textual descriptions must be returned in ascending order of distance from the camera; the nearest objects have their descriptions returned first.
Requirements: Source Images
Stable Diffusion is capable of re-contextualizing existing images. The diffusion process, in a pure text-to-image workflow, essentially takes an image consisting entirely of gaussian noise and progressively denoises the image until the result (hopefully) looks like an image described by the text prompt.

In an image-to-image workflow, the process is exactly the same except for the fact that the starting point isn't an image that is 100% noise. The input image is typically an existing drawing or photograph, and the workflow is instructed to introduce, say, 50% noise into the image, and then start the denoising process from that noisy image. This allows Stable Diffusion to essentially redraw an existing image, replacing forms and subjects by an artist-configurable amount.
For example, we can take the following rather badly-generated image:

We can feed this image into Stable Diffusion, and specify a text prompt that
reads two cups of coffee next to a coffee pot. We can specify that we want
the process to introduce 100% noise into the image before starting the
denoising process. We get the following result:

While the image is certainly coffee-themed, it bears almost no relation to the original image. This is because we specified 100% noise as the starting point; it's essentially as if we didn't bother to supply a starting image at all. If we instead specify that we want 75% noise introduced, we get the following image:

This is starting to get closer to the original image. The composition is a little closer, and the colours are starting to match. Once we specify that we want 50% noise introduced, we get the following image:

The image is very close to the original image, but the details are somewhat more refined. If we continue by going down to, say, 25% denoising, we get:

The result is, at first glance, almost indistinguishable from the original image. Now, this would be fine if we were trying to achieve photorealism and the source image we started with was already photorealistic. However, if what we have as a source image isn't photorealistic, then going below about 50% denoising constrains the generation process far too much; the resulting image will be just as unrealistic as the source image.
We have a tension between specifying a noise amount that is low enough so that the system doesn't generate an image that's completely different from our source image, but high enough to give the system enough room to improvise and (hopefully) produce a photorealistic image from a non-photorealistic input.
To produce a consistent set of source images to render a room from multiple viewpoints, we'll need to build a 3D model in Blender that contains basic colours, forms, and some lighting, but that makes no real attempt to be photorealistic. We'll depend on Stable Diffusion to take those images and produce a consistent but photorealistic output. We assume that we can't start out with photorealistic images; if we already had photographs taken in a room from all the camera angles we wanted... Why would be we using Stable Diffusion in the first place?
In practice, I've found that noise values in the range 50-55% will work. We'll come back to this later on.
Automating Prompts
As mentioned earlier, we want to be able to have Blender produce the bulk of our text prompt for us in an automated manner. We need to do the following:
- Annotate individual objects in a scene with one-sentence descriptions. For example, "A red sofa", "A potted plant with pink flowers", etc.
- When rendering an image of the scene, produce a list
Sof the objects that are actually visible from the current viewpoint. - Sort the list
Ssuch that the objects are ordered from nearest to furthest from the camera. - For each object in
S, extract the assigned text description and concatenate the descriptions into a comma-separated list for direct use in Stable Diffusion.
An example objectClass.blend scene is provided that implements all of the above.
Annotating Objects
For each of the objects in the scene, we have to create a custom string-typed
Description property on the object that contains our text prompt for that
object:
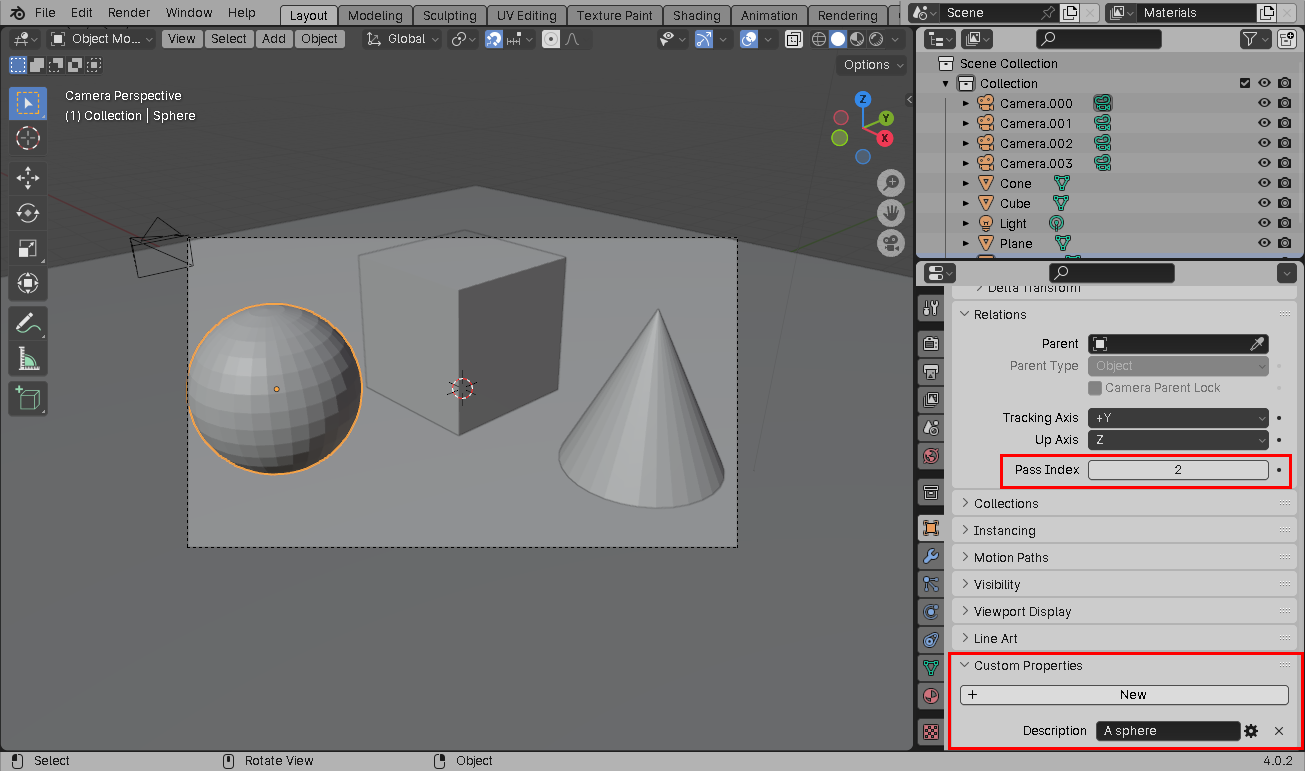
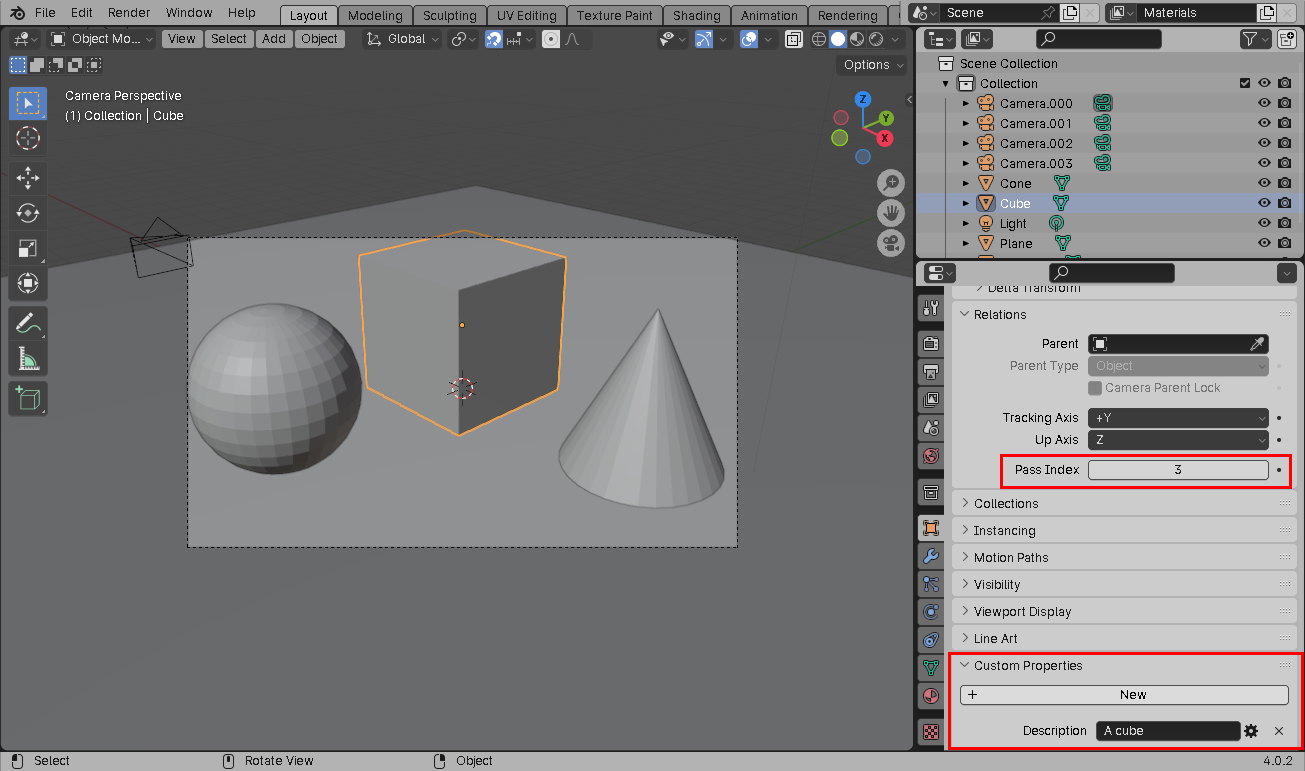
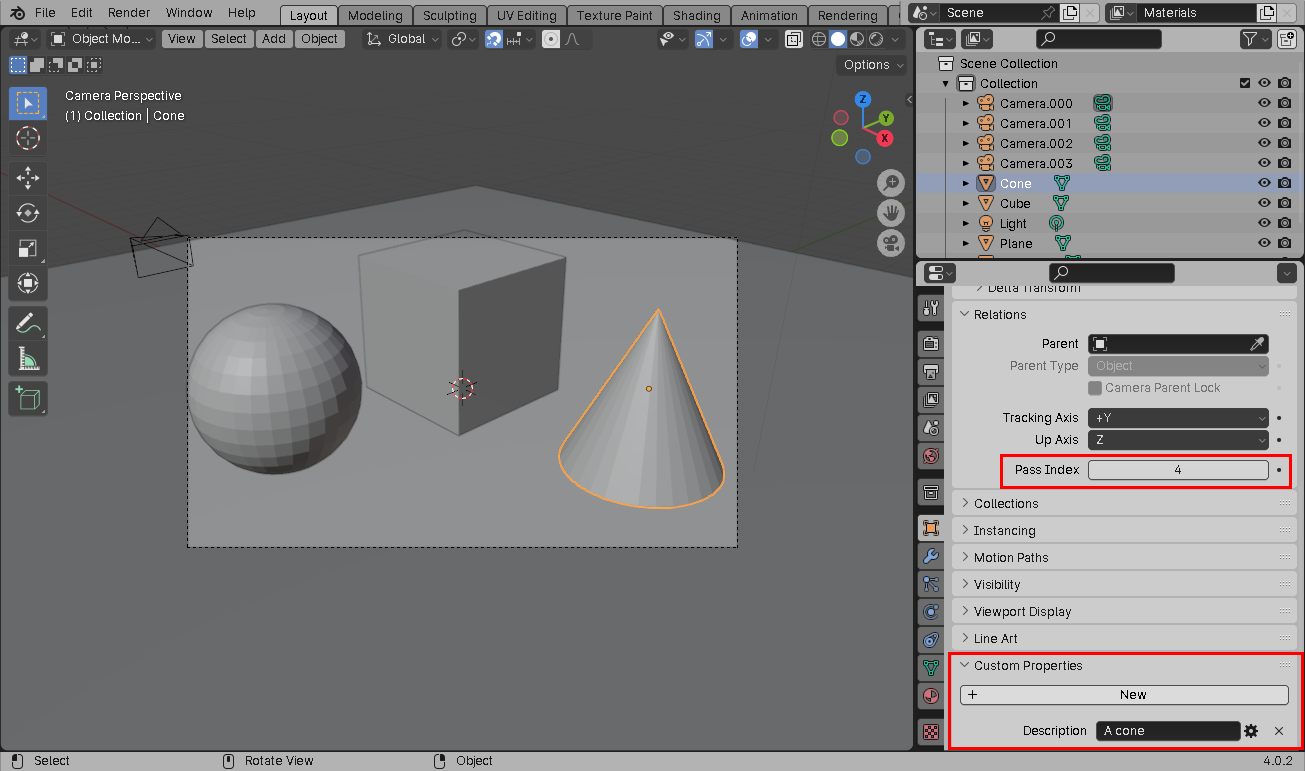
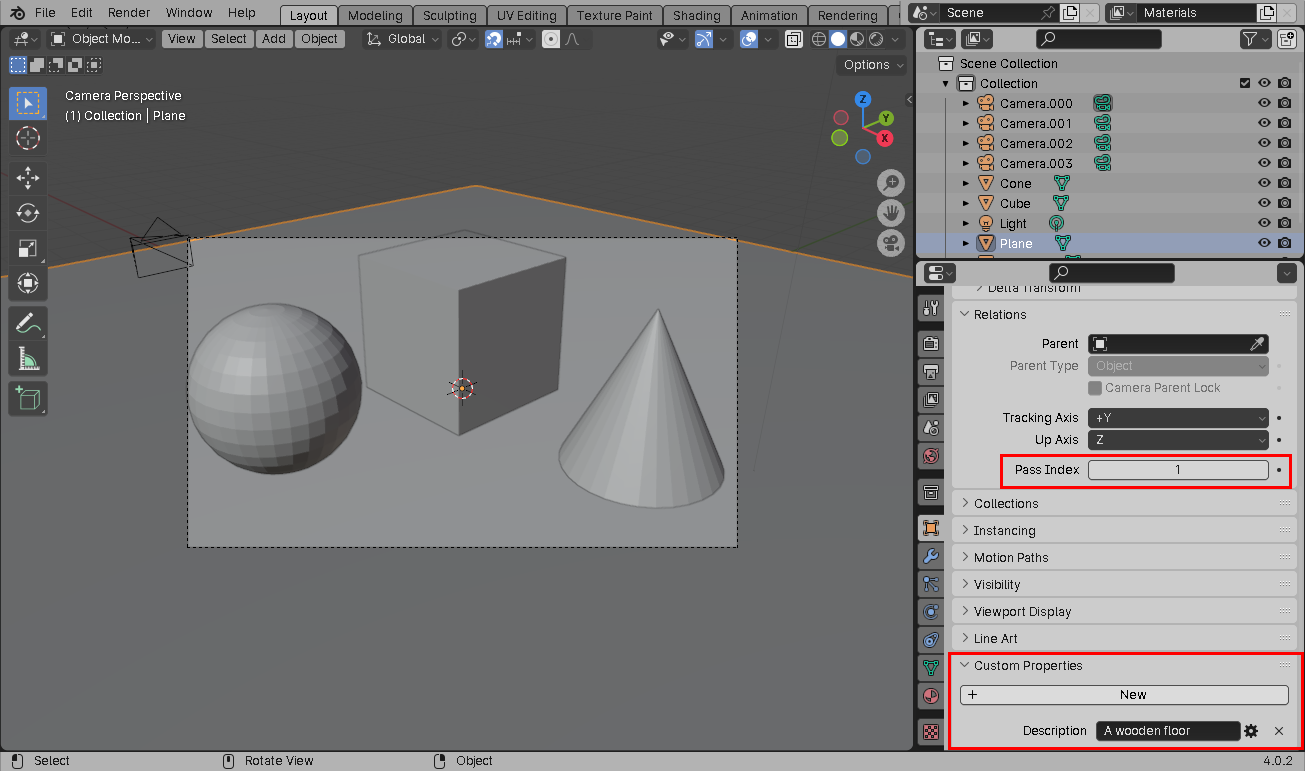
Note that we also specify a numeric, non-zero pass index for each object. Every object that has the same text prompt should have the same pass index, for reasons that will become clear shortly.
Object Visibility
Blender, unfortunately, doesn't provide an API for determining object visibility. My original line of thought was to take the frustum of the currently active camera in the scene, and calculate the set of objects that intersect that frustum. Unfortunately, this is more work than I'm willing to attempt in a clumsy language like Python, and it also wouldn't take into account whether objects in the frustum are occluded by other objects. If an object is completely hidden behind another object in the foreground, then it shouldn't appear in the text prompt.
Instead, I turned to a technique used in some forms of deferred rendering. Essentially, we render an image of the scene where each pixel in the image contains exactly one integer value denoting the numeric index of the object that produced the surface at that pixel. More specifically, the pass index that we specified for each object earlier is written directly to the output image.
For example, whilst the standard colour render output of the example scene looks like this:

The "object index pass" output looks like this (text added for clarity):
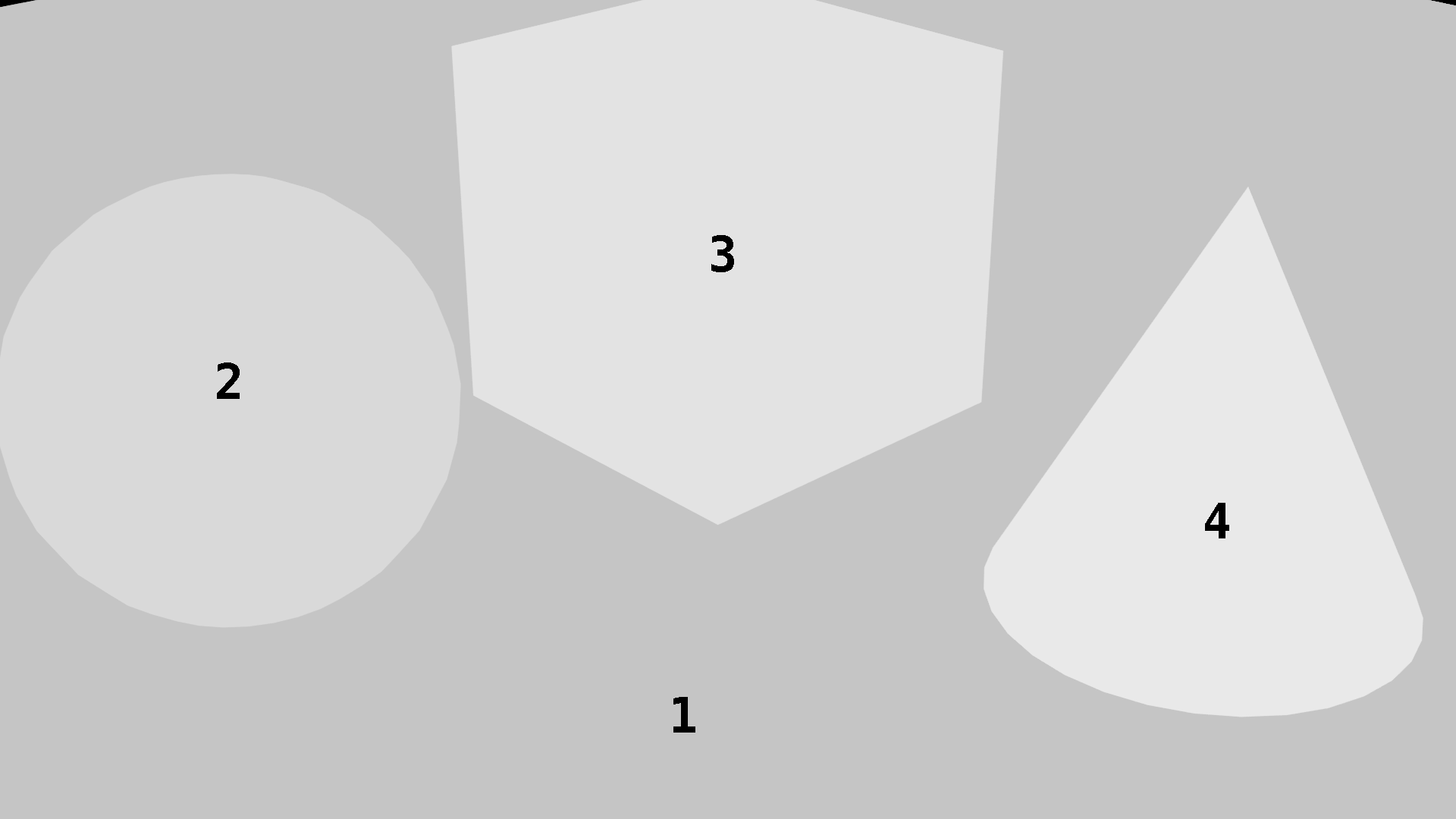
The pixels that make up the cone all have integer value 4. The pixels that
make up the sphere all have integer value 2, and so on. The pixels that make
up the background have integer value 0 (there's a tiny bit of the background
visible in the top-left corner of the image). We'll effectively ignore all
pixels with value 0.
The same scene rendered from a different viewpoint produces the following images:


Note that, from this viewpoint, the cone is almost entirely occluded by the cube.
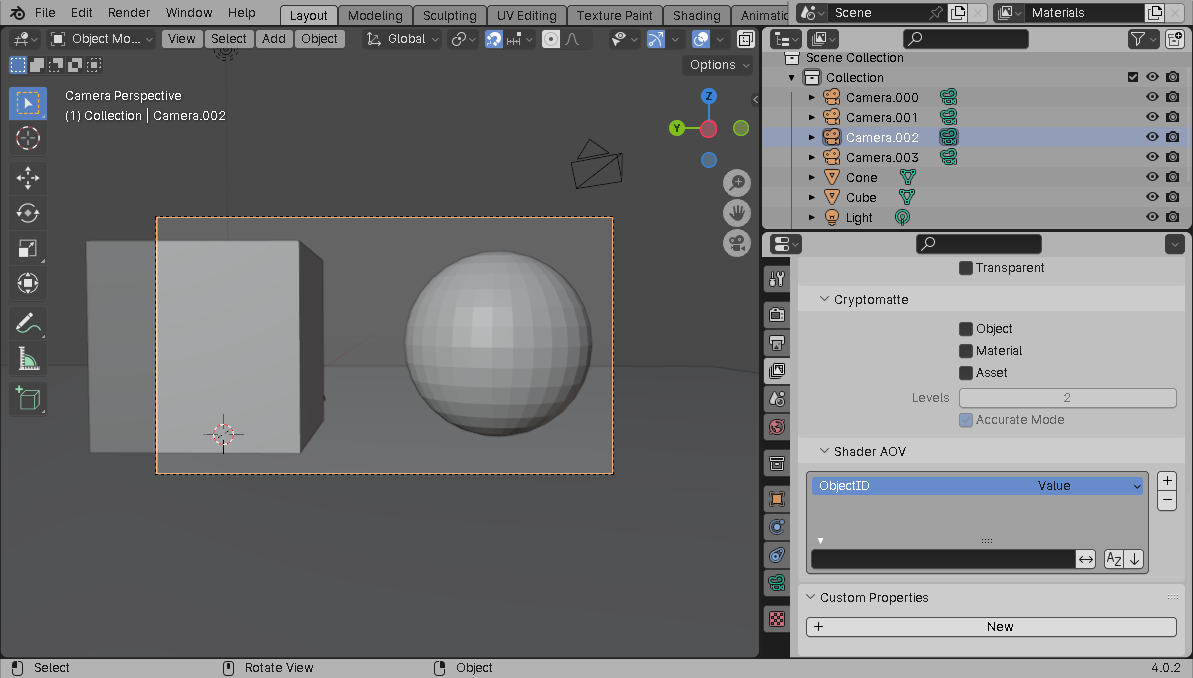
Now, unfortunately, due to a limitation in Blender, the EEVEE realtime renderer doesn't have an option to output object IDs directly as a render pass. I'm impatient and don't want to spend the time waiting for Cycles to render my scenes, so instead we can achieve the same result by using an AOV Output in each scene material.
First, create a new Value-typed AOV Output in the scene's View Layer
properties:
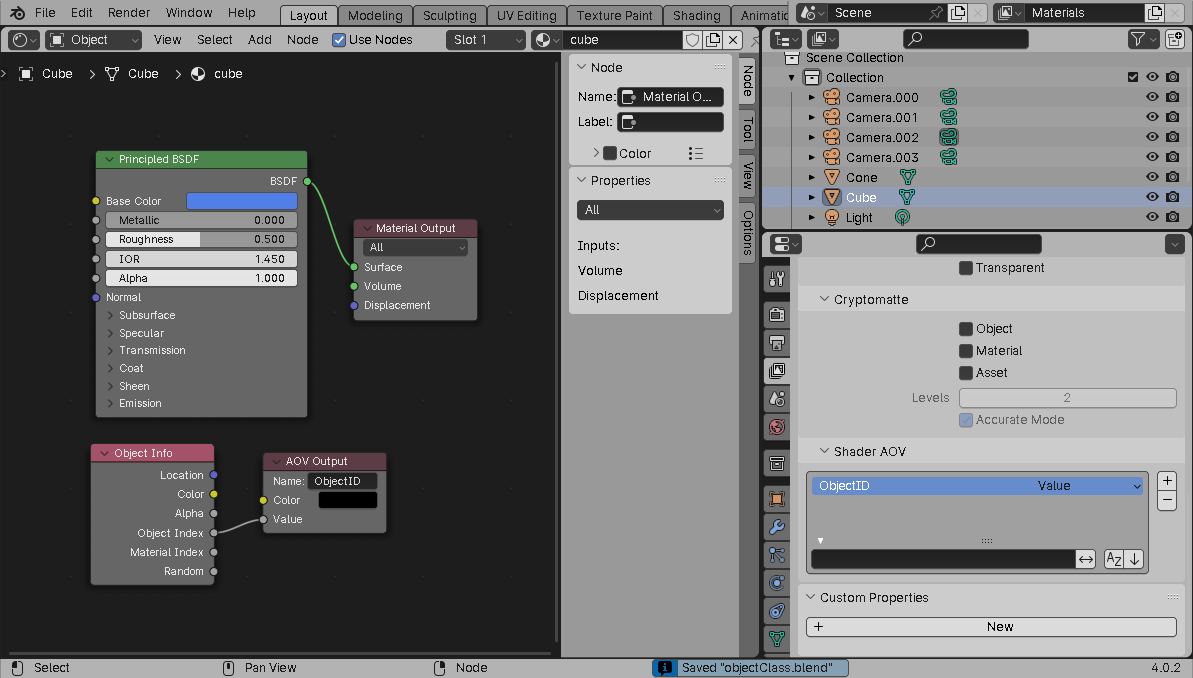
Now, for each material used in the scene, declare an AOV output node and attach the object's (confusingly named) Object Index to it:
Finally, in the Compositor settings, attach the AOV output to a Viewer Node:
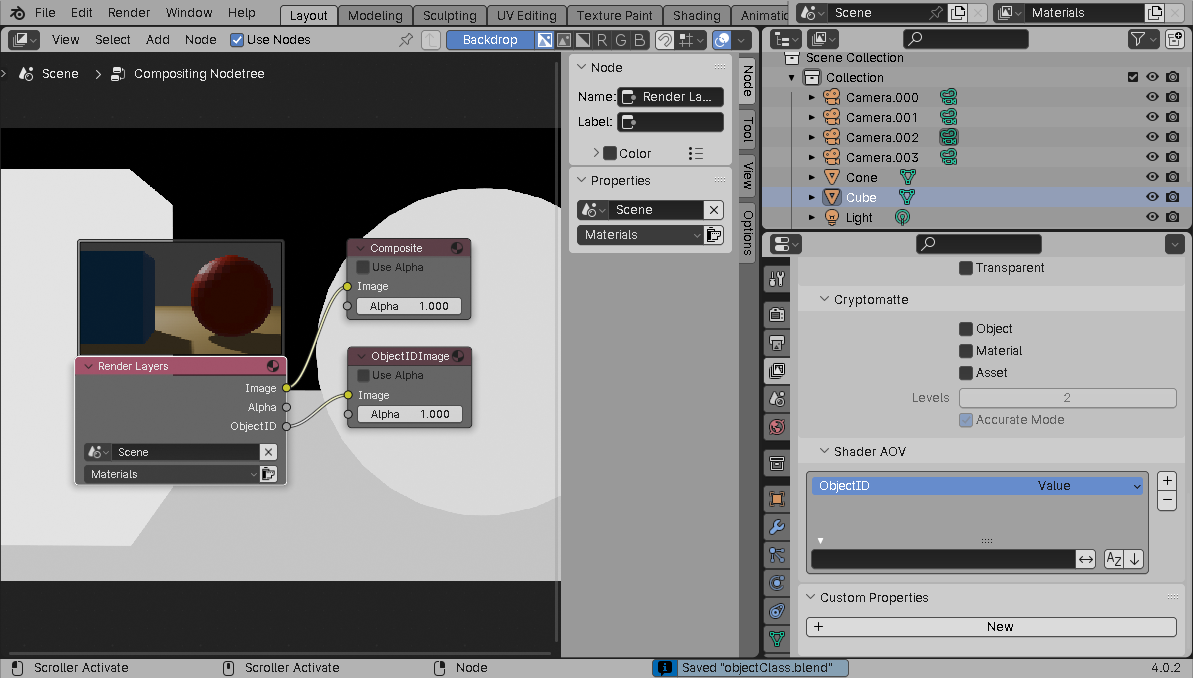
The reason for this last step is that we're about to write a script to examine the AOV image, and Blender has an infuriating internal limitation where it won't give us direct access to the pixels of a rendered image unless that rendered image came from a Viewer Node.
We now have images that can effectively tell us which objects are visible in the corresponding coloured render images. Note that we have the same limitation here as in traditional deferred rendering: We can't handle translucent or transparent objects. This hasn't, so far, turned out to be much of a problem in practice.
Producing The Prompt
We now need to write a small Python script that can take the rendered images and produce a prompt. The complete script is included as a text object in the included Blender scene, but I'll walk through the code here.
The first step is to get a reference to the currently active camera in the scene, and set up the various output files we'll be using:
import bpy
import math
import numpy
_output_directory = "/shared-tmp"
class ClassifiedObject:
index: int
distance: int
description: str
_objects = []
_camera = bpy.context.scene.camera
print('# Camera: {0}'.format(_camera.name))
_output_props = '{0}/{1}.properties'.format(_output_directory, _camera.name)
_output_prompt = '{0}/{1}.prompt.txt'.format(_output_directory, _camera.name)
_output_samples = '{0}/{1}.npy'.format(_output_directory, _camera.name)
print('# Properties: {0}'.format(_output_props))
print('# Prompt: {0}'.format(_output_prompt))
print('# Samples: {0}'.format(_output_samples))
We'll hold references to visible objects in values of type ClassifiedObject.
We then iterate over all images in the scene and calculate the euclidean distance between the origin of each object, and the camera.
def _distance_to_camera(_camera, _object):
_object_pos = _object.location
_camera_pos = _camera.location
_delta_x = _camera_pos.x - _object_pos.x
_delta_y = _camera_pos.y - _object_pos.y
_delta_z = _camera_pos.z - _object_pos.z
_delta_x_sq = _delta_x * _delta_x
_delta_y_sq = _delta_y * _delta_y
_delta_z_sq = _delta_z * _delta_z
_sum = _delta_x_sq + _delta_y_sq + _delta_z_sq
return math.sqrt(_sum)
for _o in bpy.data.objects:
if _o.pass_index:
_r = ClassifiedObject()
_r.distance = _distance_to_camera(_camera, _o)
_r.object = _o
_r.index = _o.pass_index
_r.description = _o['Description']
_objects.append(_r)
We then sort the objects we saved in ascending order of distance, so that
objects nearest to the camera appear earliest in the list, and we save the
objects to an external properties file in case we want to process them
later:
_objects.sort(key=lambda o: o.distance)
with open(_output_props, "w") as f:
for _o in _objects:
f.write('objects.{0}.index = {0}\n'.format(_o.index))
f.write('objects.{0}.description = {1}\n'.format(_o.index, _o.description))
f.write('objects.{0}.name = {1}\n'.format(_o.index, _o.object.name))
f.write('objects.{0}.distance = {1}\n'.format(_o.index, _o.distance))
We then get a reference to the image containing our integer object indices,
and save the pixels to a numpy array. Normal Python is too slow to process
images this large, so we need to do the processing using numpy to avoid
having to wait twenty or so minutes each time we want to process an image. Using
numpy, the operation is completed in a couple of seconds. The raw pixel array
returned from the viewer node is actually an RGBA image where each pixel
consists of four 32-bit floating point values. Our AOV output is automatically
expanded such that the same value will be placed into each of the four colour
channels, so we can actually avoid sampling all four channels and just use
the values in the red channel. The [::4] expression indicates that we start
from element 0, process the full length of the array, but skip forward by
4 components each time.
_image = bpy.data.images['Viewer Node'] _data = numpy.array(_image.pixels)[::4]
We now need to iterate over all the pixels in the image and count the number
of times each object index appears. Astute readers might be wondering why we
don't just maintain an int -> boolean map where we set the value of a key
to True whenever we encounter that object index in the image. There are two
reasons we can't do this.
Firstly, if an object is almost entirely occluded by another object, but a few stray pixels of the object are still visible, we don't want to be mentioning that object in the prompt. Doing so would introduce the problem discussed earlier where an object is erroneously injected into the scene by Stable Diffusion because the prompt said one should be in the scene somewhere.
Secondly, there will be pixels in the image that do not correspond to any object index. Why does this happen? Inspect the edges of objects in the AOV image from earlier:
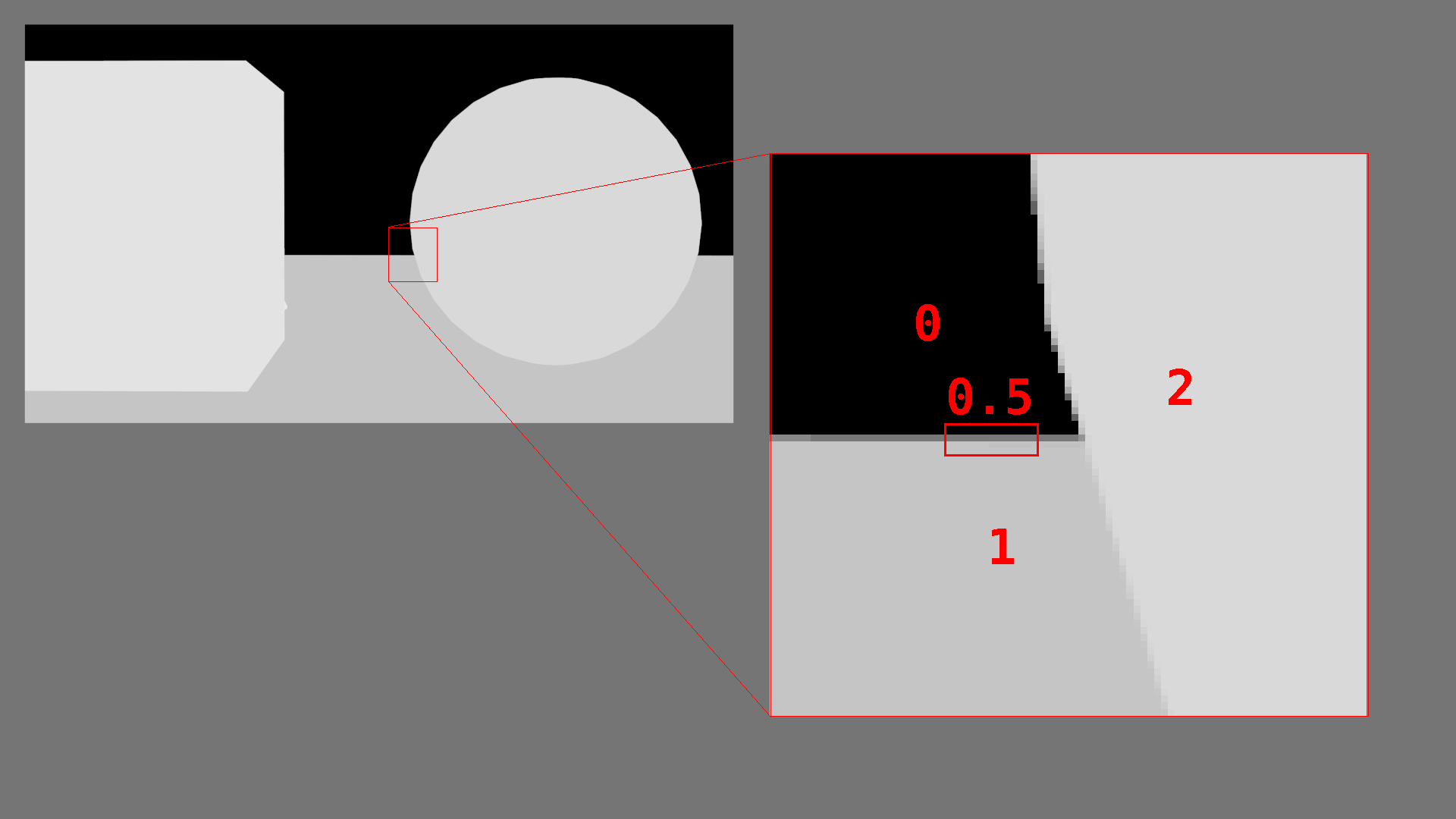
Many pixels in the image will be some linear blend of the neighbouring pixels
due to antialiasing. This will occur even if the Viewport and Render samples
are set to 1 (although it will be reduced). This is not a problem in practice,
it just means that we need to round pixel values to integers, and consider
a threshold value under which objects are assumed not to be visible. We can
accomplish this as follows:
_visibility = {}
_visibility_max = _image.size[0] * _image.size[1]
_visibility_threshold = 0.005
for _x in _data:
_xi = int(_x)
if _xi:
_c = _visibility.get(_xi) or 0
_visibility[_xi] = _c + 1
print("# Processed.")
print('# Visibility: {0}'.format(_visibility))
_visible = set()
for _i in _visibility:
_c = _visibility[_i]
_f = float(_c) / _visibility_max
if _f > _visibility_threshold:
_visible.add(_i)
print('# Visible: {0}'.format(_visible))
We calculate _visibility_max as the total number of pixels in the image.
We declare _visibility_threshold to be the threshold value at which an object
is considered to be visible. Essentially, if the pixels of an object cover more
than 0.5% of the screen, then the object is considered to be visible. Each
time we encounter a pixel that has value xi, we increment the count for
object xi in the _visibility set.
Finally, we iterate over the _visibility set and extract the indices of all
objects that were considered to be visible, given the declared threshold.
The last step simply generates the prompt. We already have the list of objects in distance order, and we know which of those objects are actually visible, so we can simply iterate over the list and write the object descriptions to a file:
with open(_output_prompt, 'w') as f:
for _o in _objects:
if _o.index in _visible:
f.write('{0},\n'.format(_o.description))
This prompt file can be consumed directly by Stable Diffusion in ComfyUI using a text file node.
To run the script (assuming the script is in a text block in Blender's text
editor), we simply render the scene and then, with the text editor selected,
press ALT-P to run the script.
This image:
... Produces this output on Blender's console:
# Camera: Camera.002
# Properties: /shared-tmp/Camera.002.properties
# Prompt: /shared-tmp/Camera.002.prompt.txt
# Samples: /shared-tmp/Camera.002.npy
# Processing 2073600 elements...
# Processed.
# Visibility: {1: 453103, 2: 481314, 3: 616150, 4: 85}
# Visible: {1, 2, 3}
# Saved.
Note that it correctly determined that objects 1, 2, and 3 are visible
(the floor, the sphere, and the cube, respectively). The cone was not considered
to be visible. The resulting prompt was:
A sphere, A cube, A wooden floor,
From the other viewpoint:
... The following output and prompt is produced:
# Camera: Camera.000
# Properties: /shared-tmp/Camera.000.properties
# Prompt: /shared-tmp/Camera.000.prompt.txt
# Samples: /shared-tmp/Camera.000.npy
# Processing 2073600 elements...
# Processed.
# Visibility: {1: 1144784, 2: 287860, 3: 408275, 4: 232240}
# Visible: {1, 2, 3, 4}
# Saved.
A sphere, A cone, A cube, A wooden floor,
Note how the cube and floor are mentioned last, as they are furthest away.
In Practice
Using the above techniques, I built a small house in Blender, populated it with objects, and took the following renders:
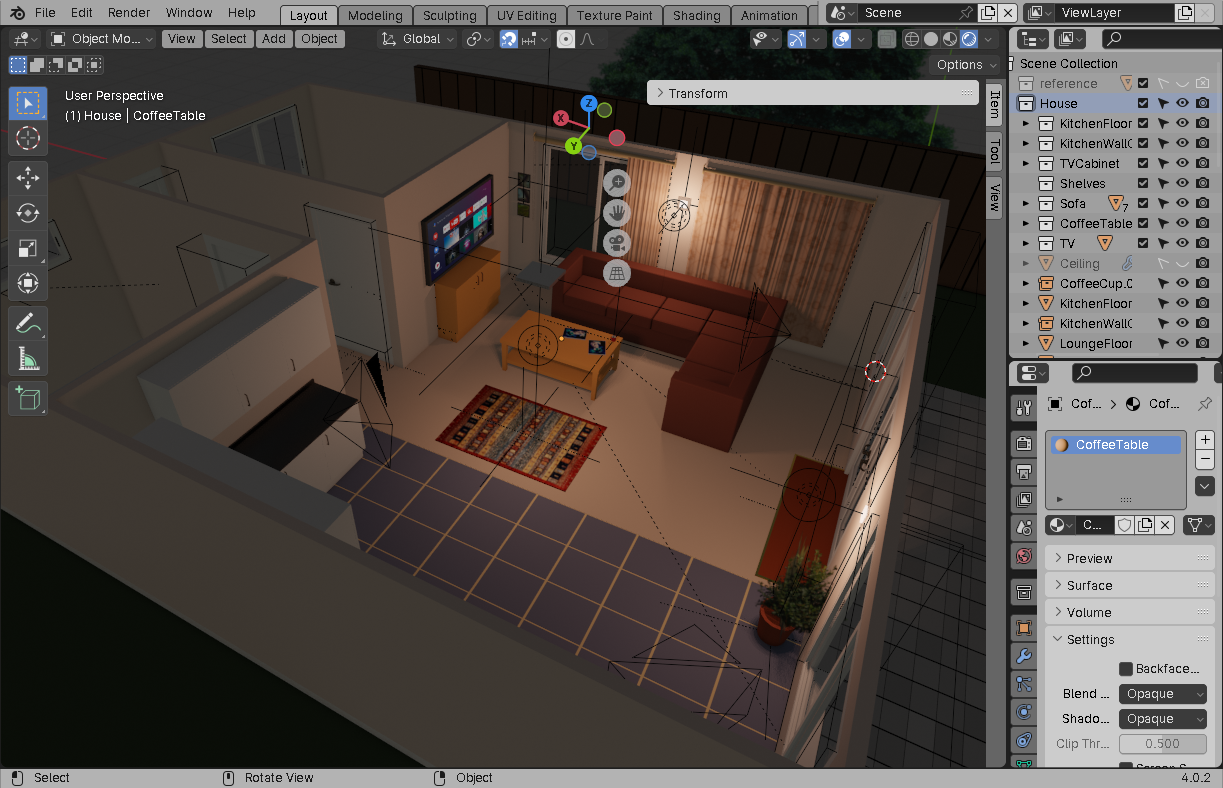



No attempt was made at photorealism. I took care to only provide objects with minimal forms and textures (often just flat colours). I ran the images through an image-to-image workflow at approximately 52% denoising, and received the following images:



While by no means perfect, the room is at least recognizable as being the same room from different angles. With some more precise prompting and some minor inpainting, I believe the room could be made completely consistent between shots.
We must negate the machines-that-think. Humans must set their own guidelines. This is not something machines can do. Reasoning depends upon programming, not on hardware, and we are the ultimate program! Our Jihad is a "dump program." We dump the things which destroy us as humans!
— Frank Herbert, Children of Dune