In a recent post to the bndtools-users mailing list, I
expressed a bit of frustration with my experience of trying out
Bndtools for what I think must be about
the fourth time. Jürgen Albert had mentioned on the osgi-dev
list that he had a working environment where, every time he
clicked "Save" in his IDE, bundles would automatically be built
and deployed to a running OSGi container.
This gave him effectively live updates to running code during development. I'd still not
been able to achieve this in my Maven
and IDEA environment,
so I took another look at Bndtools to see if it could be
done. Any OSGi user will be familiar with being able to deploy
new parts of a running system without having to restart it, but
actually being able to instantly deploy code every time you change
as little as a single line of code is probably not something that
every OSGi user has access to.
On the bndtools-users list, Raymond Auge mentioned to me that he'd
recently added functionality to an as-yet-unreleased version of the
bnd-run-maven-plugin
that might be able to solve the problem. It worked beautifully!
Using the following setup, it's possible to get live code updates
without having to stray outside of a traditional Maven setup; your
build gets to remain a conventional Maven build and, if you don't
use the feature, you probably don't have to know the plugin exists
at all.
The setup described here assumes a multi-module Maven project. I describe it in these terms because all of my projects are multi-module, and it should be trivial to infer, for anyone familiar with Maven, the simpler single-module setup given the more complex multi-module setup.
A complete, working example project is available on GitHub. The example project contains:
com.io7m.bndtest.api: A simple API specification for hello world programs.com.io7m.bndtest.vanilla: An implementation of thecom.io7m.bndtest.apispec.com.io7m.bndtest.main: A consumer of thecom.io7m.bndtest.apispec; it looks up an implementation and uses it.com.io7m.bndtest.run: Administrative information for setting up an OSGi runtime.
At the time of writing, the version of the bnd-run-maven-plugin
you need is currently only available as a development snapshot.
Add the following pluginRepository to the root POM of your
Maven project:
<pluginRepositories>
<pluginRepository>
<id>bnd-snapshots</id>
<url>https://bndtools.jfrog.io/bndtools/libs-snapshot/</url>
<layout>default</layout>
<releases>
<enabled>false</enabled>
</releases>
</pluginRepository>
</pluginRepositories>
This will no longer be necessary once version 4.3.0 is officially
released.
Add an execution of this plugin in the root POM of your project:
<build>
<plugins>
...
<plugin>
<groupId>biz.aQute.bnd</groupId>
<artifactId>bnd-run-maven-plugin</artifactId>
<version>4.3.0-SNAPSHOT</version>
</plugin>
</plugins>
</build>
Add a module to your project (in the example code, this is com.io7m.bndtest.run) that will be used to declare
the information and dependencies required to start a basic
OSGi runtime. In this case, I use Felix
and install a minimal set of services such as a Gogo shell and Declarative Services.
These aren't necessary for the plugin to function, but the example
code on GitHub uses Declarative Services, and the Gogo shell makes
it easier to poke around in the OSGi runtime to see what's going on.
The POM file for this module should contain dependencies for all of the bundles you wish to install into the OSGi runtime, and all the OSGi framework and services. In my case this looks like:
<dependencies>
<dependency>
<groupId>${project.groupId}</groupId>
<artifactId>com.io7m.bndtest.api</artifactId>
<version>${project.version}</version>
</dependency>
<dependency>
<groupId>${project.groupId}</groupId>
<artifactId>com.io7m.bndtest.vanilla</artifactId>
<version>${project.version}</version>
</dependency>
<dependency>
<groupId>${project.groupId}</groupId>
<artifactId>com.io7m.bndtest.main</artifactId>
<version>${project.version}</version>
</dependency>
<dependency>
<groupId>org.apache.felix</groupId>
<artifactId>org.apache.felix.framework</artifactId>
</dependency>
<dependency>
<groupId>org.apache.felix</groupId>
<artifactId>org.apache.felix.gogo.shell</artifactId>
</dependency>
<dependency>
<groupId>org.apache.felix</groupId>
<artifactId>org.apache.felix.gogo.command</artifactId>
</dependency>
<dependency>
<groupId>org.apache.felix</groupId>
<artifactId>org.apache.felix.shell.remote</artifactId>
</dependency>
<dependency>
<groupId>org.apache.felix</groupId>
<artifactId>org.apache.felix.shell</artifactId>
</dependency>
<dependency>
<groupId>org.apache.felix</groupId>
<artifactId>org.apache.felix.scr</artifactId>
</dependency>
<dependency>
<groupId>org.apache.felix</groupId>
<artifactId>org.apache.felix.log</artifactId>
</dependency>
<dependency>
<groupId>org.osgi</groupId>
<artifactId>osgi.promise</artifactId>
</dependency>
</dependencies>
A single execution of the bnd-run-maven-plugin is needed in this
module, along with a simple bndrun file. Note that the name of the
plugin exection must be unique across the entire set
of modules in the Maven reactor. You will be referring to this name
later on the command line, so pick a sensible name (we use main
here). Note that the name of the bndrun file can be completely
arbitrary; the name of the file does not have to be in any way
related to the name of the plugin execution.
<build>
<plugins>
<plugin>
<groupId>biz.aQute.bnd</groupId>
<artifactId>bnd-run-maven-plugin</artifactId>
<executions>
<execution>
<id>main</id>
<configuration>
<bndrun>main.bndrun</bndrun>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
The main.bndrun file is unsurprising to anyone with a passing
familiarity with bnd. We specify that we want Felix to be the
OSGi framework, and we list the set of bundles that should be
installed and executed. We don't bother to specify version numbers
because this information is already present in the Maven POM.
$ cat main.bndrun -runfw: \ org.apache.felix.framework -runee: JavaSE-11 -runrequires: \ osgi.identity;filter:='(osgi.identity=com.io7m.bndtest.main)' -runbundles: \ com.io7m.bndtest.api, \ com.io7m.bndtest.main, \ com.io7m.bndtest.vanilla, \ org.apache.felix.gogo.command, \ org.apache.felix.gogo.runtime, \ org.apache.felix.gogo.shell, \ org.apache.felix.log, \ org.apache.felix.scr, \ org.apache.felix.shell, \ org.apache.felix.shell.remote, \ osgi.promise, \
Now that all of this is configured, it's necessary to do a
full Maven build and execute the plugin. Note that, due to
a Maven limitation, it is necessary to call the bnd-run-maven-plugin
in the same operation as the package lifecycle. In other
words, execute this:
$ mvn package bnd-run:run@main
The @main suffix to the run command refers to the named main
execution we declared earlier. The above command will run a Maven
build and then start an OSGi instance and keep it in the foreground:
$ mvn package bnd-run:run@main
[INFO] Scanning for projects...
[INFO] ------------------------------------------------------------------------
[INFO] Reactor Build Order:
[INFO]
[INFO] com.io7m.bndtest [pom]
[INFO] com.io7m.bndtest.api [jar]
[INFO] com.io7m.bndtest.vanilla [jar]
[INFO] com.io7m.bndtest.main [jar]
[INFO] com.io7m.bndtest.run [jar]
...
[INFO] ---------------< com.io7m.bndtest:com.io7m.bndtest.run >----------------
[INFO] Building com.io7m.bndtest.run 0.0.1-SNAPSHOT [5/5]
[INFO] --------------------------------[ jar ]---------------------------------
[INFO]
...
[INFO] --- bnd-run-maven-plugin:4.3.0-SNAPSHOT:run (main) @ com.io7m.bndtest.run ---
____________________________
Welcome to Apache Felix Gogo
g! lb
START LEVEL 1
ID|State |Level|Name
0|Active | 0|System Bundle (6.0.3)|6.0.3
1|Active | 1|com.io7m.bndtest.api 0.0.1-SNAPSHOT - Bnd experiment (API) (0.0.1.201905160844)|0.0.1.201905160844
2|Active | 1|com.io7m.bndtest.main 0.0.1-SNAPSHOT - Bnd experiment (Main consumer) (0.0.1.201905160845)|0.0.1.201905160845
3|Active | 1|com.io7m.bndtest.vanilla 0.0.1-SNAPSHOT - Bnd experiment (Vanilla implementation) (0.0.1.201905160845)|0.0.1.201905160845
4|Active | 1|Apache Felix Gogo Command (1.1.0)|1.1.0
5|Active | 1|Apache Felix Gogo Runtime (1.1.2)|1.1.2
6|Active | 1|Apache Felix Gogo Shell (1.1.2)|1.1.2
7|Active | 1|Apache Felix Log Service (1.2.0)|1.2.0
8|Active | 1|Apache Felix Declarative Services (2.1.16)|2.1.16
9|Active | 1|Apache Felix Shell Service (1.4.3)|1.4.3
10|Active | 1|Apache Felix Remote Shell (1.2.0)|1.2.0
11|Active | 1|org.osgi:osgi.promise (7.0.1.201810101357)|7.0.1.201810101357
At this point, there is a running OSGi container in the foreground.
The bnd-run-maven-plugin is monitoring the jar files that were created
as part of the Maven build and, if those jar files are changed, the plugin will
notify the framework that it's necessary to reload the code.
Now, given that we want to make rebuilding and updating running code as quick as possible, we almost certainly don't want to have to do a full Maven build every time we change a line of code. Luckily, we can configure IDEA to do the absolute minimum amount of work necessary to achieve this.
First, open the Run Configurations window:
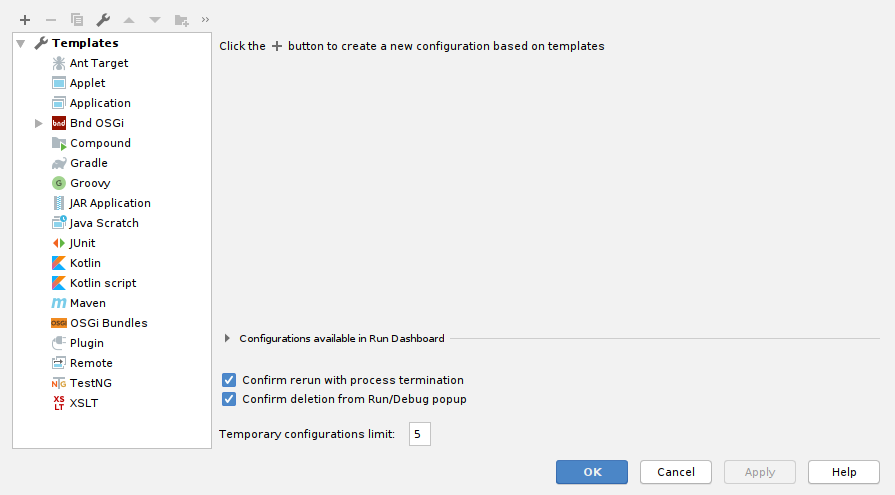
Add a Maven build configuration:
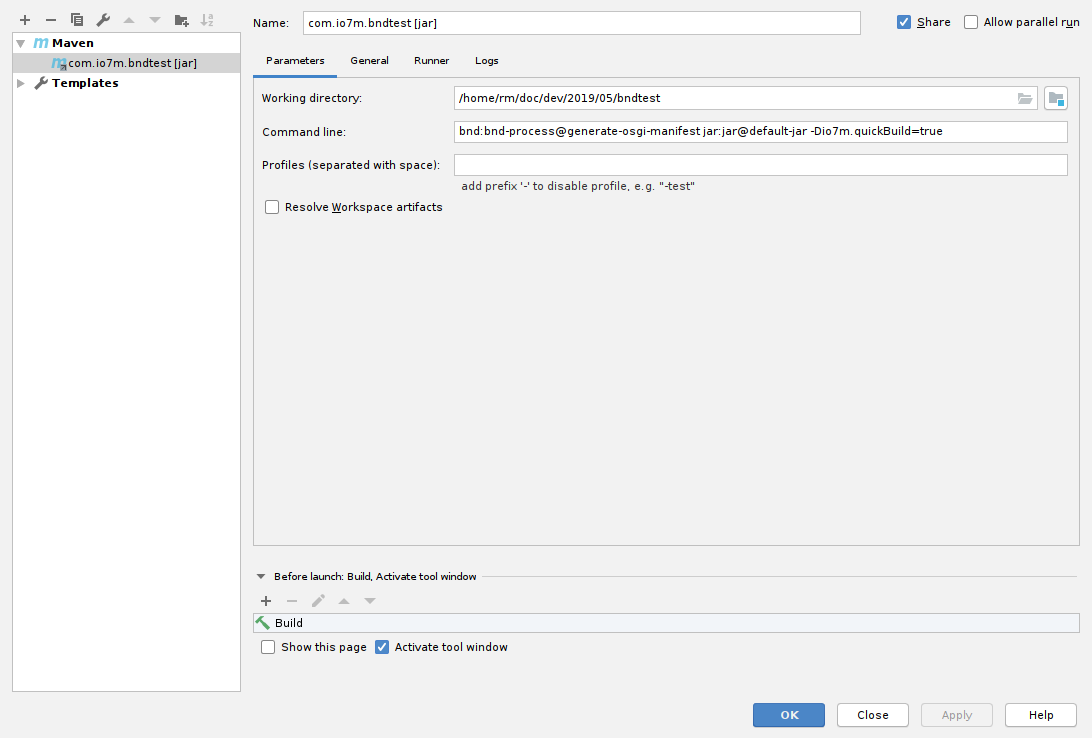
The precise Maven command-line used will depend on your
project setup. In the example code, I have an execution of the
bnd-maven-plugin named generate-osgi-manifest that does the work
necessary to create an OSGi manifest. I also have an execution of the
maven-jar-plugin named default-jar that adds the generated manifest
to the created jar file. I also declare a property io7m.quickBuild
which turns off any plugin executions that aren't strictly necessary
during development. All of these things are configurations declared
in the primogenitor
parent POM that I use for all projects, but none of them should
be in any way unfamiliar to anyone that has put together a basic
bnd-maven-plugin-based project. The gist is: Tell Maven to run
the bnd-maven-plugin and generate an OSGi manifest for each module,
and then tell it to create a jar for each module.
The other important item is to add a Before Launch option (at the bottom of the window) that runs a normal IDE build before Maven is executed. The reason for this is speed: We want the IDE to very quickly rebuild class files (this is essentially instant on my system), and then we want to execute the absolute bare minimum in terms of Maven goals after the IDE build.
One small nit here: The root module of your project will almost certainly
have a packaging of type pom instead of type jar. The bnd-maven-plugin
will (correctly) skip the creation of a manifest file for this module, and
this will then typically cause the maven-jar-plugin to complain that there
is no manifest file to be inserted into the jar that it's creating. A quick
and dirty workaround is to do this in the root of the project:
mkdir -p target/classes/META-INF touch target/classes/META-INF/MANIFEST.MF
In the example project, I include a small run.sh script that actually does
this as part of starting up the OSGi container:
#!/bin/sh mkdir -p target/classes/META-INF touch target/classes/META-INF/MANIFEST.MF exec mvn package bnd-run:run@main
I strongly recommend not doing this as part of the actual Maven build itself; this is something that's only needed by developers who are making use of this live code updating setup during development, and isn't something that the Maven build needs to know about. By executing specific plugins, we're not calling Maven in the way that it would normally be called and therefore it's up to us to ensure that things are set up correctly so that the plugins can work.
With both of these things configured, we should now be able to click Run
in IDEA, and the code will be built in a matter of seconds:
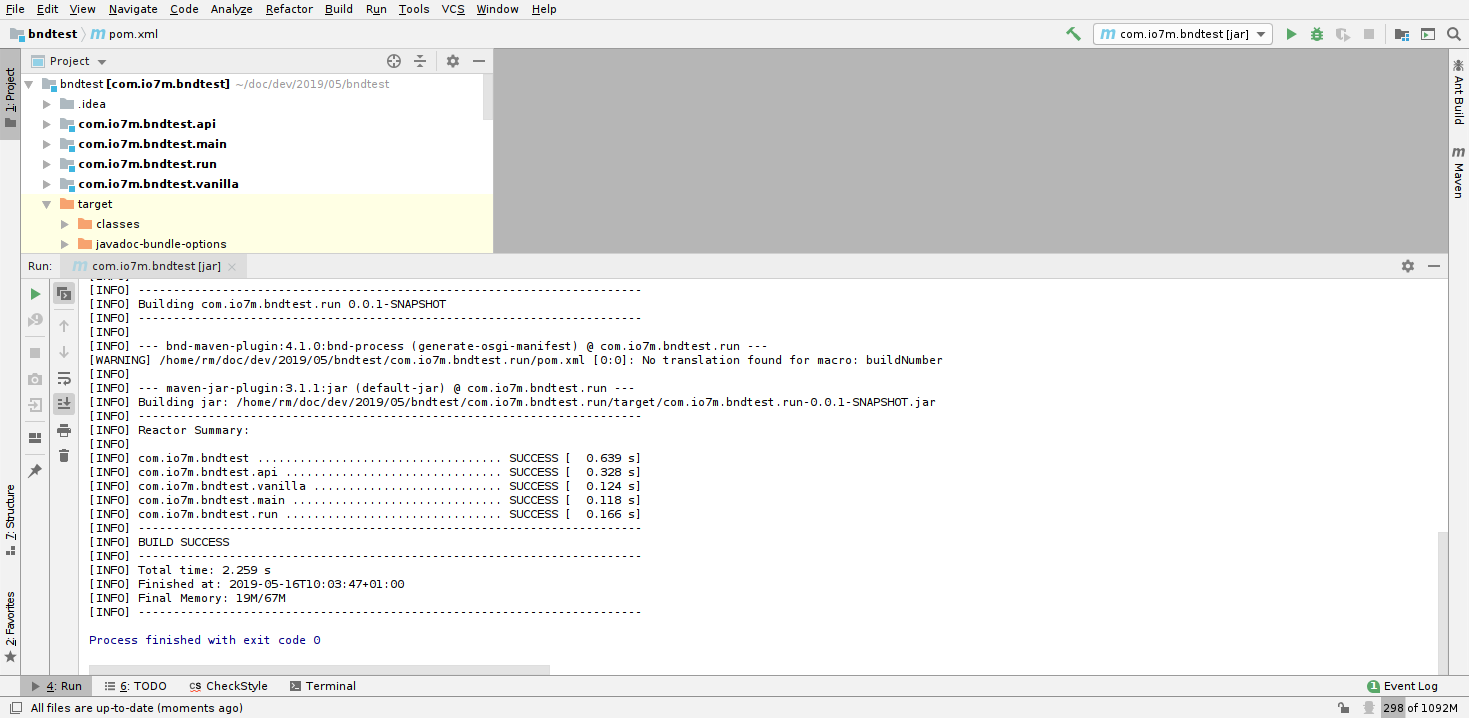
Assuming that our OSGi container is still running somewhere, the rebuilt jar files will be detected and the code will be reloaded automatically:
[INFO] Detected change to /home/rm/doc/dev/2019/05/bndtest/com.io7m.bndtest.api/target/com.io7m.bndtest.api-0.0.1-SNAPSHOT.jar. Reloading. Speak: onDeactivate Speak: onActivate Speak: Hello again, again!
Once again, OSGi demonstrates how unique it currently is: I don't know of any other system that provides a type-safe, version-safe, dynamic update system such as this. I know of other systems that do it dangerously, or in a type-unsafe way, or without the benefits of strong API versioning, but none that do things as safely and correctly as OSGi.
In the past couple of years, I've gotten back into composing music after a fifteen year break. I had originally stopped making music without any expectation that I'd ever do it again. Making music had become extremely stressful due to two factors: economics, and proprietary software. Briefly, I'd assumed that I needed to make money from music because I believed I had no other skills. This lead to a very fear-driven and unpleasant composition process more suited to producing periodic mild mental breakdowns than listenable music. Additionally, all of the software I was using to make music was the standard vendor lock-in proprietary fare; That's a nice studio you have here, it'd be a shame if you stopped paying thousands of monetary units per year to keep it working exactly the same way it always has and something happened to it... What? You want to use some different software and migrate your existing data to it? Ha ha ha! You're not going anywhere!
So I gave up and got into software instead. Fast forward fifteen years and now, as a (presumably) successful self-employed software engineer and IT consultant, economics are no longer a factor. Additionally, after fifteen years of using, contributing to, developing, and publishing open-source software, coupled with huge advances in the quality of all of the available open-source music software - I no longer have any desire or use for proprietary audio software. There is nothing that any proprietary audio software vendor can offer me that I could conceivably want.
As I mentioned, my music composition process in the distant past had been very fear-driven, and I'd accumulated a ton of rather destructive mental habits. However, fifteen years of meditation and other somewhat occult practices have left with me the tools needed to recognize, identify, and extinguish those mental habits.
One habit that I identified very early turned out to be one that was common amongst other musicians I know. Specifically: Too much detail too soon. In essence, it's very easy in modern electronic music composition environments to write four bars of music (looping the music continuously as you write), and progressively add more and more detail to the music, and do more and more tuning and adjustments to the sounds. Before long, eight hours have passed and you have four very impressive bars of music, and no idea whatsoever as to what the next four bars are going to be. Worse, you've essentially induced a mild hypnotic trance by listening to the same section of music over and over, and have unconsciously cemented the idea into your mind that these four bars of music are going to be immediately followed by the same four bars. Even worse; you've almost certainly introduced a set of very expensive (in terms of computing resources here, but perhaps in terms of monetary cost too, if you're that way inclined) electronic instruments and effects in an attempt to get the sound just the way you like it, and you may now find that it's practically impossible to write any more music because the amount of electronic rigging has become unwieldy. If you're especially unlucky, you may have run out of computing resources. Better hope you can write the rest of the music using only those instrument and plugin instances you already have, because you're not going to be creating any more!
Once I'd identified this habit, I looked at ways to eliminate it before it could manifest. I wanted to ensure that I'd written the entirety of the music of the piece before I did any work whatsoever on sounds or production values. The first attempt at this involved painstakingly writing out a physical score in MuseScore using only the built-in general MIDI instruments. The plan was to then take the score and recontextualize it using electronic instruments, effects, et cetera. In other words, the composition would be explicitly broken up into stages: Write the music, use the completed music as raw MIDI input to a production environment, and then manipulate the audio, add effects, and so on to produce a piece that someone might actually want to listen to. As an added bonus, I'd presumably come away with a strong understanding of the music-theoretic underpinnings of the resulting piece, and I'd also be forced into making the actual music itself interesting because I'd not be able to rely on using exciting sounds to maintain my own interest during the composition process.
The result was successful, but I'd not try it again; having to write out a score using a user interface that continually enforces well-formed notation is far too time consuming and makes it too difficult to experiment with instrument lines that have unusual timing. MuseScore is an excellent program for transcribing music, but it's an extremely painful and slow environment for composition. In defense of MuseScore: I don't think it's really intended for composition.
Subsequent attempts to compose involved writing music in a plain MIDI sequencer on a piano roll, but using only a limited number of FM synth instances. Dexed, specifically. These attempts were mostly successful, but I still felt a tendency to play with and adjust the sounds of the synthesizers as I wrote. The problem was that the sounds that Dexed produced were actually good enough to be used as the final result, and I was specifically trying to avoid doing anything that could be used as a final result at this stage of the composition.
So, back to the drawing board again. I reasoned that the problem was down to using sounds that could conceivably appear in the final recording and, quite frankly, being allowed any control whatsoever over the sounds. An obvious solution presented itself: Write the music using the worst General MIDI sound module you can find. Naming no names, I found a freely-available SoundFontⓡ that sounded exactly like a low-budget early 90s sound module. Naturally, I could never publish music that used a General MIDI sound module with a straight face. This would ensure that I wrote all the music first without any possibility of spending any time playing with sounds and then (and only then) could I move to re-recording the finished music in an environment that had sounds that I could actually tolerate.
Attempts to compose music in this manner were again successful, but it became apparent that General MIDI was a problem. The issue is that General MIDI sound modules attempt to (for the most part) emulate actual physical acoustic instruments. This means that if you're presented with the sound of a flute, you'll almost certainly end up writing monophonic musical lines that could conceivably be played on a flute. The choice of instrument sound inevitably influences the kind of musical lines that you'll write.
What I wanted were sounds that:
-
Sounded bad. This ensures that the sounds chosen during the writing of the music won't be the sounds that are used in the final released version of the piece.
-
Sounded different to each other. A musician who's opinion I respect suggested that I use pure sine waves. The problem with this approach is that once you have four or five sine wave voices working in counterpoint, it becomes extremely hard to work out which voice is which. I need sounds that are functionally interchangeable and yet are recognizably distinct.
-
Sounded abstract. I don't want to have any idea what instrument the sound is supposed to represent. It's better if it doesn't represent any particular instrument; I don't want to be unconsciously guided to writing xylophone-like or brass-like musical lines just because the sound I randomly pick sounds like a xylophone or trumpet.
-
Required little or no computing resources. I want to be able to have lots of instruments without being in any way concerned about computing resource use. Additionally, I don't want to deal with any synthesizer implementation bugs during composition.
Reviewing all the options, I decided that the best way to achieve the above would be to produce a custom SoundFontⓡ. There are multiple open source implementations available that can play SoundFontⓡ files, and all of them are light on resource requirements and appear to lack bugs. I wanted a font that contained a large range of essentially unrecognizable sounds, all of which could be sustained indefinitely whilst a note is held. There were no existing tools for the automated production of SoundFontⓡ files, so I set to work:
-
jsamplebuffer provides a simple Java API to make it easier to work with buffers of audio samples.
-
jnoisetype provides a Java API and command-line tools to read and write SoundFontⓡ files.
I then went through hundreds of Dexed presets collected from freely-available
DX7 patch banks online, and collected 96 sounds that were appropriately
different from each other. I put together some Ardour
project files used to export the sounds from Dexed instances into FLAC
files that could be sliced up programatically and inserted into a SoundFontⓡ
file for use in implementations such as FluidSynth.
The result: Unbolted Frontiers.
A SoundFontⓡ that no sensible person could ever want to use. 96 instruments using substandard 22khz audio samples, each possessing the sole positive quality that they don't sound much like any of the others. Every note is overlaid with a pure sine wave to assist with the fact that FM synthesis tends to lead to sounds that have louder sideband frequencies than they do fundamental frequencies. All instruments achieve sustain with a simple crossfade loop. Hopefully, none of the instruments sound much like any known acoustic instrument. The only percussion sounds available sound like someone playing a TR-808 loudly and badly.
If I hear these sounds used in recorded music, I'm going to be very disappointed.
It's that time of year again.
-----BEGIN PGP SIGNED MESSAGE----- Hash: SHA512 Fingerprint | Comment - ------------------------------------------------------------------------ E379 5957 1613 1DB4 E7AB 87DD 67B1 8CC1 F9AC E345 | 2019 maven-rsa-key D345 CCB7 187B C973 BDD4 9192 BEC8 33E4 DCAA 5330 | 2019 android commit signing DD3E 9631 2A83 748C B4B3 73A5 91A8 14E2 EAF7 50A3 | 2019 release-signing 33E7 E23B F949 E558 A333 38E3 562B F636 4C42 DA2E | 2019 maven-rsa-key -----BEGIN PGP SIGNATURE----- iHUEARYKAB0WIQTjeVlXFhMdtOerh91nsYzB+azjRQUCXCuhgwAKCRBnsYzB+azj ReAKAQCdag7RQljpNSdNZKe6Yd59cWsyk2N3dPZzyj1epjdVlgD/aqzs13xoKkJn uycYrtoIXLbo2cEFmPleL0/CI8f4gA8= =1ziK -----END PGP SIGNATURE-----
Keys are published to the keyservers as usual.
I do a bit of 3D rendering now and then using Blender. Blender has multiple rendering engines: Blender Internal and Cycles. Blender Internal is a 1990s style CPU-based raytracer, and Cycles is a physically-based renderer that can be executed on either CPUs or GPUs. Cycles is technologically superior to Blender Internal in every way except for one: The performance when running on CPUs is essentially hopeless. In order to get reasonable render times, you really need a powerful GPU with an appropriate level of driver support. I refuse to use proprietary hardware drivers for both practical reasons and reasons of principle. This has meant that, to date, I haven't been able to use Cycles with GPU acceleration and have therefore stuck to using Blender Internal. As I don't aim for photorealism in anything I render (I prefer a sort of obviously-rendered pseudo-impressionist style), Blender Internal has been mostly sufficient.
However, I've recently moved to rendering 1080p video at 60fps. This means that even if it only takes ~10 seconds to render a single frame, that's still about 35 hours of rendering time to produce a 3.5 minute video.
I have a few machines around the place here that spend a fair amount
of time mostly idle. I decided to look for ways to distribute rendering
tasks across machines to use up the idle CPU time. The first thing I
looked at was netrender.
Unfortunately, netrender is both broken and abandonware. I spent
a good few hours spinning up VM instances and trying to get it to
work, but it didn't happen.
I've been using Jenkins for a while now to build and test code from hundreds of repositories that I maintain. I decided to see if it could be useful here... After a day or so of experimentation, it turns out that it makes an acceptable driver for a render farm!
I created a set of nodes used for rendering tasks. A node in
Jenkins speak is an agent program running on a computer that accepts
commands such as "check out this code now", "build this code now",
etc. I won't bother to go into detail on this, as setting up nodes
is something anyone with any Jenkins experience already knows how
to do. Nodes can be assigned labels so that tasks can be assigned
to specific machines. For example, you could add a linux label to
machines running Linux, and then if you had software that would only
build on Linux, you could set that job to only run on nodes that
are labelled with linux. Basically, I created one node for each
idle machine here and labelled them all with a blender label to
distinguish them from the nodes I use to build code.
I then placed my Blender project and all of the required assets into a Git repository.
I created a new job in Jenkins that checks out the git repository above and runs the following pipeline definition included in the repository:
#!groovy
// Required: https://plugins.jenkins.io/pipeline-utility-steps
node {
def nodes = nodesByLabel label:"blender"
def nodesSorted = nodes.sort().toList()
def nodeTasks = [:]
def nodeCount = nodesSorted.size()
for (int i = 0; i < nodeCount; ++i) {
def nodeName = nodesSorted[i]
def thisNodeIndex = i
nodeTasks[nodeName] = {
node(nodeName) {
stage(nodeName) {
checkout scm
sh "./render.sh ${thisNodeIndex} ${nodeCount}"
}
}
}
}
parallel nodeTasks
}
This uses the pipeline-utility-steps
plugin to fetch a list of online nodes with a particular label from Jenkins. I make
the simplifying assumption that all online nodes with the blender label will be
participating in render tasks. I assign each node a number, and I create a new task
that will run on each node that runs a render.sh shell script from the repository.
The tasks are executed in parallel and the job is completed once all subtasks have
run to completion.
The render.sh shell script is responsible for executing Blender.
Blender has a full command-line interface for rendering images without opening
a user interface. The main command line parameters we're interested in are:
blender \
--background \
coldplanet_lofi.blend \
--scene Scene \
--render-output "${OUTPUT}/########.png" \
--render-format PNG \
--frame-start "${NODE_INDEX}" \
--frame-end "${FRAME_COUNT}" \
--frame-jump "${NODE_COUNT}" \
--render-anim
The --frame-start parameter indicates at which frame the node should start
rendering. The --frame-end parameter indicates the last frame to render. The
--frame-jump parameter indicates the number of frames to step forward each
time. We pass in the node index (starting at 0) as the starting frame,
and the number of nodes that are participating in rendering as the frame
jump. Let's say there are 4 nodes rendering: Node 0 will start at
frame 0, and will then render frame 4, then frame 8, and so on. Node
1 will start at frame 1, then render frame 5, and so on. This means
that the work will be divided up equally between the nodes. There are
no data dependencies between frames, so the work parallelizes easily.
When Jenkins is instructed to run the job, all of the machines pull the git repository and start rendering. At the end of the task, they upload all of their rendered frames to a server here in order to be stitched together into a video using ffmpeg. Initial results seem promising. I'm rendering with three nodes, and rendering times are roughly 30% of what they were with just the one node. I can't really ask for more than that.
There are some weaknesses to this approach:
-
Rendering can't be easily resumed if the job is stopped. This could possibly be mitigated by building more intelligence into the
render.shfile, but maybe not. -
Work is divided up equally, but nodes are not equal. I initially tried adding a node to the pool of nodes that was much slower than the others. It was assigned the same amount of work as the other nodes, but took far longer to finish. As a result, the work actually took longer than it would have if that node hadn't been involved at all. In fact, in the initial tests, it took longer than rendering on a single node!
-
There's not really a pleasant way to estimate how much longer rendering is going to take. It's pretty hard to read the console output from each machine in the Jenkins UI.
Finally: All of this work is probably going to be irrelevant very soon. Blender 2.8 has a new realtime rendering engine - EEVEE - which should presumably mean that rendering 3.5 minutes of video will take me 3.5 minutes.
Big thanks to Aleksey Shipilev for adding file lists and sizes to builds.shipilev.net so that CoffeePick can efficiently enumerate builds on the site.
A new repository provider has been added to CoffeePick that can fetch
nightly builds from the builds.shipilev.net repository:
User directory: /home/rm/local/coffeepick Loading repositories… INFO com.io7m.coffeepick.client.vanilla.CoffeePickCatalog: setting up repository from provider net.shipilev.builds (urn:net.shipilev.builds) INFO com.io7m.coffeepick.client.vanilla.CoffeePickCatalog: setting up repository from provider net.java.jdk (urn:net.java.jdk) INFO com.io7m.coffeepick.client.vanilla.CoffeePickCatalog: setting up repository from provider net.adoptopenjdk.raw (urn:net.adoptopenjdk.raw) [coffeepick]$ catalog repository:urn:net.shipilev.builds ID | Arch | Platform | Version | VM | Conf | Size | Repository | Tags 41640365d898abb9c333cc7137a0b9a97ed05ad8 | aarch64 | linux | 11.0.1+13 | hotspot | jdk | 106.13 MB | urn:net.shipilev.builds | fastdebug nightly 5b4c02ea37cedf1ba3c5cee208749e4a539ce808 | aarch64 | linux | 11.0.1+13 | hotspot | jdk | 112.88 MB | urn:net.shipilev.builds | nightly release 37e1d1e3c93e4aae6dc7dac233f50f149ba40806 | aarch64 | linux | 11.0.1+13 | hotspot | jdk | 112.88 MB | urn:net.shipilev.builds | nightly release 187b3c3f00e6f808964fc2486383ef73d1cb6a0c | aarch64 | linux | 11.0.1+13 | hotspot | jdk | 106.15 MB | urn:net.shipilev.builds | fastdebug nightly 5f232d58300791fba0452c41710390c630df959a | aarch64 | linux | 11.0.1+13 | hotspot | jdk | 76.31 MB | urn:net.shipilev.builds | nightly slowdebug f48f5257256b6ef01398cbbcc077af81bde4f817 | aarch64 | linux | 11.0.1+13 | hotspot | jdk | 76.31 MB | urn:net.shipilev.builds | nightly slowdebug 8b7b663db1b82ebc4f886b60b9adca34e3a9ca28 | arm32-hflt | linux | 11.0.1+13 | hotspot | jdk | 96.43 MB | urn:net.shipilev.builds | fastdebug nightly 4c65bbb79e7f28d11b292618977a65242881eed8 | arm32-hflt | linux | 11.0.1+13 | hotspot | jdk | 103.26 MB | urn:net.shipilev.builds | nightly release e9d61d87e265ee8f2b167f9e83bfccc450adf823 | arm32-hflt | linux | 11.0.1+13 | hotspot | jdk | 71.16 MB | urn:net.shipilev.builds | nightly slowdebug 048d498ab77c049a34da88d70b1e838bae2c1947 | arm32-hflt | linux | 11.0.1+13 | hotspot | jdk | 96.43 MB | urn:net.shipilev.builds | fastdebug nightly 0abf8507da0c49e425cd689bb63b9b66336edc5c | arm32-hflt | linux | 11.0.1+13 | hotspot | jdk | 103.25 MB | urn:net.shipilev.builds | nightly release 8e86c6d5b7705e97e3401361638a405640b0b3e4 | arm32-hflt | linux | 11.0.1+13 | hotspot | jdk | 71.17 MB | urn:net.shipilev.builds | nightly slowdebug 7ef78d8a19a9b7cf51b34e2e6d51ce0500fd29ef | ppc64le | linux | 11.0.1+13 | hotspot | jdk | 72.42 MB | urn:net.shipilev.builds | nightly slowdebug 397837245e66717feed96b27fac7af28c0597cab | ppc64le | linux | 11.0.1+13 | hotspot | jdk | 101.83 MB | urn:net.shipilev.builds | fastdebug nightly 53a22d756a40af3cc968d71adcf77664dd6c50ca | ppc64le | linux | 11.0.1+13 | hotspot | jdk | 72.41 MB | urn:net.shipilev.builds | nightly slowdebug 74e15bb1e3d6ca67015b8ae58db3f9db525d4ab6 | ppc64le | linux | 11.0.1+13 | hotspot | jdk | 104.80 MB | urn:net.shipilev.builds | nightly release fa1e016a654eb31b255a03a2328e8bdd82d5a72d | ppc64le | linux | 11.0.1+13 | hotspot | jdk | 104.81 MB | urn:net.shipilev.builds | nightly release 5b46c15abbafb4b8a7e684e5144b109f6bce939a | ppc64le | linux | 11.0.1+13 | hotspot | jdk | 101.84 MB | urn:net.shipilev.builds | fastdebug nightly 7f78d67f3a8268a70bf399d15d88e4292dfa0544 | s390x | linux | 11.0.1+13 | hotspot | jdk | 102.60 MB | urn:net.shipilev.builds | nightly release 664bd29cad89d18f63bc8000d1f598577fe1afae | s390x | linux | 11.0.1+13 | hotspot | jdk | 74.13 MB | urn:net.shipilev.builds | nightly slowdebug a6d23644361b735bafb00a687aa8c008b24dfedd | s390x | linux | 11.0.1+13 | hotspot | jdk | 99.01 MB | urn:net.shipilev.builds | fastdebug nightly 191333a141ca461e4957327f58a94f603c3facc4 | s390x | linux | 11.0.1+13 | hotspot | jdk | 102.60 MB | urn:net.shipilev.builds | nightly release aea5eacb3ae7a1f2591e55b5a4fdd0704765478a | s390x | linux | 11.0.1+13 | hotspot | jdk | 99.01 MB | urn:net.shipilev.builds | fastdebug nightly 721b3beaba3612c851853ba3bcd898255630809c | s390x | linux | 11.0.1+13 | hotspot | jdk | 74.14 MB | urn:net.shipilev.builds | nightly slowdebug ed79993ad7f3c45b06c574729e508702c7d80ce7 | x32 | linux | 11.0.1+13 | hotspot | jdk | 75.74 MB | urn:net.shipilev.builds | nightly slowdebug abb921fbf12ea8078f84d02ed849f04c79b8a356 | x32 | linux | 11.0.1+13 | hotspot | jdk | 75.74 MB | urn:net.shipilev.builds | nightly slowdebug 5bccd1116c63498c7a818e6fb0b5177dc297e89c | x32 | linux | 11.0.1+13 | hotspot | jdk | 100.89 MB | urn:net.shipilev.builds | fastdebug nightly a96ae066a52ee2104925cfb78c9c364c537e86f1 | x32 | linux | 11.0.1+13 | hotspot | jdk | 105.84 MB | urn:net.shipilev.builds | nightly release c56dd229eae9fdf17f0386eb97b21e5d8199828d | x32 | linux | 11.0.1+13 | hotspot | jdk | 105.83 MB | urn:net.shipilev.builds | nightly release 3d0fa3fd4b21766d4ac97cfba195ce851120aa7a | x32 | linux | 11.0.1+13 | hotspot | jdk | 100.90 MB | urn:net.shipilev.builds | fastdebug nightly 19d78ca22dc1d3271c1bece1a282bf521968f5b3 | x64 | linux | 11.0.1+13 | hotspot | jdk | 118.52 MB | urn:net.shipilev.builds | fastdebug nightly 38d9f40ec59efa9004ac17ca0e71cd34f8b8a571 | x64 | linux | 11.0.1+13 | hotspot | jdk | 84.17 MB | urn:net.shipilev.builds | nightly slowdebug 0644ad607da9baf66c921d8ca70f3377d04dbb61 | x64 | linux | 11.0.1+13 | hotspot | jdk | 116.13 MB | urn:net.shipilev.builds | nightly release 59f8d3fd009ba14aa1996ab6398cbd0d646eb334 | x64 | linux | 11.0.1+13 | hotspot | jdk | 84.21 MB | urn:net.shipilev.builds | nightly slowdebug bb38ac99481d336ebb6fa7e19bbdec0827bc46a7 | x64 | linux | 11.0.1+13 | hotspot | jdk | 118.51 MB | urn:net.shipilev.builds | fastdebug nightly 97e000c96535e3bc3efdb381828a218820a8ecdb | x64 | linux | 11.0.1+13 | hotspot | jdk | 116.13 MB | urn:net.shipilev.builds | nightly release da39a3ee5e6b4b0d3255bfef95601890afd80709 | x64 | linux | 12+17 | hotspot | jdk | 0.00 MB | urn:net.shipilev.builds | nightly panama release af012b2040669390547481a2452217d09353e0e1 | x64 | linux | 12+17 | hotspot | jdk | 259.83 MB | urn:net.shipilev.builds | nightly panama release 0cf94d49148737b832167122d6f5f4fdaf801ae3 | x64 | linux | 12+17 | hotspot | jdk | 483.00 MB | urn:net.shipilev.builds | fastdebug nightly panama 3ebbf4488ceaaab2d228f6efe2628c13f4bc9e28 | aarch64 | linux | 12+19 | hotspot | jdk | 78.04 MB | urn:net.shipilev.builds | nightly portola slowdebug d069f34f3e0db3fd70269c8f547ae57754bc3c0b | aarch64 | linux | 12+19 | hotspot | jdk | 78.04 MB | urn:net.shipilev.builds | nightly portola slowdebug 49862778ffae5a5cc97b253aee542bcdcd3a1884 | aarch64 | linux | 12+19 | hotspot | jdk | 115.82 MB | urn:net.shipilev.builds | nightly portola release e0f8da3c26430dfee6481f7f0adafbfd06f8ffe0 | aarch64 | linux | 12+19 | hotspot | jdk | 115.82 MB | urn:net.shipilev.builds | nightly portola release 4307401874eb05bffa22ed29b9399d9abe0d73a6 | aarch64 | linux | 12+19 | hotspot | jdk | 108.33 MB | urn:net.shipilev.builds | fastdebug nightly portola 8955e33a74f18861248f98127c5179dc3f2617e6 | aarch64 | linux | 12+19 | hotspot | jdk | 108.32 MB | urn:net.shipilev.builds | fastdebug nightly portola 16672bc7757b6bc9ecd5e2794c991a0efbe10b49 | arm32-hflt | linux | 12+19 | hotspot | jdk | 72.11 MB | urn:net.shipilev.builds | nightly portola slowdebug 345f3a07d1e33f6222e6161b67d1f708c1575b9f | arm32-hflt | linux | 12+19 | hotspot | jdk | 97.88 MB | urn:net.shipilev.builds | fastdebug nightly portola 3fab8c3241645d865d7e03656d0a08b549ff05ad | arm32-hflt | linux | 12+19 | hotspot | jdk | 97.90 MB | urn:net.shipilev.builds | fastdebug nightly portola bc89b28ec9bd43f4bbb412c5ed7b3e55ad433a34 | arm32-hflt | linux | 12+19 | hotspot | jdk | 105.73 MB | urn:net.shipilev.builds | nightly portola release 2c709cfa67ea4f8100252b7782d0a4fb38a8b86d | arm32-hflt | linux | 12+19 | hotspot | jdk | 105.75 MB | urn:net.shipilev.builds | nightly portola release 115a35a0d94b334d86c166650969491194e84687 | arm32-hflt | linux | 12+19 | hotspot | jdk | 72.10 MB | urn:net.shipilev.builds | nightly portola slowdebug e0aaf73d5d3f7f646b455c2c0373d1ddd9f231c5 | ppc64le | linux | 12+19 | hotspot | jdk | 74.06 MB | urn:net.shipilev.builds | nightly portola slowdebug b8251432135b5531696dd242ae836972afdc9702 | ppc64le | linux | 12+19 | hotspot | jdk | 107.41 MB | urn:net.shipilev.builds | nightly portola release ec09bec89d375ccf4a0dd1e52fb406b29bb40fd3 | ppc64le | linux | 12+19 | hotspot | jdk | 107.42 MB | urn:net.shipilev.builds | nightly portola release f1be1843c36b638cd18cbf9f65850fa70fbd064d | ppc64le | linux | 12+19 | hotspot | jdk | 104.03 MB | urn:net.shipilev.builds | fastdebug nightly portola 3a64a1ea13b212c619d044de07c4a59abdefd00e | ppc64le | linux | 12+19 | hotspot | jdk | 74.07 MB | urn:net.shipilev.builds | nightly portola slowdebug 7904aee58d724134490c00e1d832ebb4038ba441 | ppc64le | linux | 12+19 | hotspot | jdk | 104.03 MB | urn:net.shipilev.builds | fastdebug nightly portola 3dcb14f1467a5167b018409a5969efe8c1981f23 | s390x | linux | 12+19 | hotspot | jdk | 105.12 MB | urn:net.shipilev.builds | nightly portola release 7e66bb2d88f84789cd3b07ae147e5ebf833f6b68 | s390x | linux | 12+19 | hotspot | jdk | 75.90 MB | urn:net.shipilev.builds | nightly portola slowdebug 0100a992f9766cd24c503f0bf46ab7e048b5439d | s390x | linux | 12+19 | hotspot | jdk | 101.13 MB | urn:net.shipilev.builds | fastdebug nightly portola ee1566ff3b73fa2e158a6f010efc537b42d786dc | x32 | linux | 12+19 | hotspot | jdk | 103.12 MB | urn:net.shipilev.builds | fastdebug nightly portola 6ced70a0ad89236fd5a984c9ec5086f35d0d18de | x32 | linux | 12+19 | hotspot | jdk | 77.18 MB | urn:net.shipilev.builds | nightly portola slowdebug 4c34a20445e3d18e5a3d9f30b3ee259d16d70c6d | x32 | linux | 12+19 | hotspot | jdk | 103.12 MB | urn:net.shipilev.builds | fastdebug nightly portola 73d44c8f77437a996fb41a540200f3922c83938c | x32 | linux | 12+19 | hotspot | jdk | 108.36 MB | urn:net.shipilev.builds | nightly portola release 946be78a0bded6ca6ff29180ba3eb29716138bbc | x32 | linux | 12+19 | hotspot | jdk | 108.36 MB | urn:net.shipilev.builds | nightly portola release 3ab16dd10776df10db8ff1ca8b86a820095fa7f6 | x32 | linux | 12+19 | hotspot | jdk | 77.18 MB | urn:net.shipilev.builds | nightly portola slowdebug e9cf741f9f1041288acba6ef51a58f56734c9453 | x64 | linux | 12+19 | hotspot | jdk | 90.48 MB | urn:net.shipilev.builds | nightly portola slowdebug 77dae05ff29d75be451cc338c7e4d2d4db173ad1 | x64 | linux | 12+19 | hotspot | jdk | 125.29 MB | urn:net.shipilev.builds | fastdebug nightly portola a4948372aadb182e969a6f6a8b9c50ce06083038 | x64 | linux | 12+19 | hotspot | jdk | 123.17 MB | urn:net.shipilev.builds | nightly portola release 173e23107b290aaf5ab02ee412bdbe28afa85e61 | x64 | linux | 12+19 | hotspot | jdk | 90.46 MB | urn:net.shipilev.builds | nightly portola slowdebug 16b2ebbb175d07e42e1e870f57cbf3a18ce2b3c7 | x64 | linux | 12+19 | hotspot | jdk | 125.31 MB | urn:net.shipilev.builds | fastdebug nightly portola 014622da9eeef042e637547351810167b7554d53 | x64 | linux | 12+19 | hotspot | jdk | 123.18 MB | urn:net.shipilev.builds | nightly portola release 67d50df977a824e5f7402ea45fa501206d6cb649 | x64 | windows | 12+19 | hotspot | jdk | 184.64 MB | urn:net.shipilev.builds | nightly portola release a91f415b5cb19ebd634345ee63d949d090065b40 | x64 | windows | 12+19 | hotspot | jdk | 73.52 MB | urn:net.shipilev.builds | nightly portola slowdebug 4b691a3ef30c725b180e6a354f975d22452fd045 | x64 | windows | 12+19 | hotspot | jdk | 73.61 MB | urn:net.shipilev.builds | fastdebug nightly portola 2876e3343569b9951d99e2c8f7cfc7007e75b44d | x64 | linux | 12+20 | hotspot | jdk | 379.91 MB | urn:net.shipilev.builds | fastdebug loom nightly 3250317ea3d23e01156953cdd65301a29ccebf58 | x64 | linux | 12+20 | hotspot | jdk | 303.42 MB | urn:net.shipilev.builds | loom nightly slowdebug 9e7ad5a7b31ca6c6b9a9306dcb8d1962c5850145 | x64 | linux | 12+20 | hotspot | jdk | 176.75 MB | urn:net.shipilev.builds | loom nightly release 36205f634a9cdd5abafb30b42636a1c5e5ad99c5 | x64 | windows | 12+20 | hotspot | jdk | 0.00 MB | urn:net.shipilev.builds | loom nightly release fec8d2443b4a57ce8f18a88703583741e8c1dc9a | x64 | windows | 12+20 | hotspot | jdk | 0.00 MB | urn:net.shipilev.builds | fastdebug loom nightly 73973947e6a1d2c7a6eaf9791673f719bd6a497b | x64 | windows | 12+20 | hotspot | jdk | 0.00 MB | urn:net.shipilev.builds | loom nightly slowdebug e5813af65d68c5010c3aa800d352e19cc68de947 | aarch64 | linux | 12+21 | hotspot | jdk | 274.82 MB | urn:net.shipilev.builds | nightly slowdebug 87f957dfeca75e33cdd674454512a44e0068fa2a | aarch64 | linux | 12+21 | hotspot | jdk | 79.25 MB | urn:net.shipilev.builds | nightly shenandoah slowdebug 8c19561bf207fccd4c7cb2f51a48480d8e09870d | aarch64 | linux | 12+21 | hotspot | jdk | 105.63 MB | urn:net.shipilev.builds | fastdebug nightly zgc 11819eed76a7d55ad0a9885341b59d8d9462cb57 | aarch64 | linux | 12+21 | hotspot | jdk | 76.97 MB | urn:net.shipilev.builds | nightly slowdebug zgc d720238f22652fd0e3ecdf97c1bdfff6e48def65 | aarch64 | linux | 12+21 | hotspot | jdk | 111.91 MB | urn:net.shipilev.builds | fastdebug nightly shenandoah ddf0983c023a040fdef297fe016a9a053f42cd3c | aarch64 | linux | 12+21 | hotspot | jdk | 339.94 MB | urn:net.shipilev.builds | fastdebug nightly 5ff676fed75604c289aa1d911240aef54abbd60d | aarch64 | linux | 12+21 | hotspot | jdk | 105.63 MB | urn:net.shipilev.builds | fastdebug nightly zgc e9de27d1fc1d0ae90c5dc85f1ebd89fa978108a8 | aarch64 | linux | 12+21 | hotspot | jdk | 105.49 MB | urn:net.shipilev.builds | fastdebug nightly 745d065650be81df59dd5245b69e7abf8e284ebb | aarch64 | linux | 12+21 | hotspot | jdk | 116.27 MB | urn:net.shipilev.builds | nightly release e07a73ef61a4900ebd9f9924e5cd7704a31d154d | aarch64 | linux | 12+21 | hotspot | jdk | 116.45 MB | urn:net.shipilev.builds | nightly release shenandoah 145562434577023a90f9d5dcefb40c9cf49f18ef | aarch64 | linux | 12+21 | hotspot | jdk | 116.46 MB | urn:net.shipilev.builds | nightly release shenandoah 0b1d2725e89945ec939eeedc1bcf849d96b4a0fb | aarch64 | linux | 12+21 | hotspot | jdk | 76.95 MB | urn:net.shipilev.builds | nightly slowdebug zgc fde14b9d88d1bd39b00df2ee65ab2b0cd34cdffe | aarch64 | linux | 12+21 | hotspot | jdk | 111.91 MB | urn:net.shipilev.builds | fastdebug nightly shenandoah 91757fdcf3091bdbdf60c127f164fb2dab645891 | aarch64 | linux | 12+21 | hotspot | jdk | 169.43 MB | urn:net.shipilev.builds | nightly release 68e33ab821e388b847d9f9eef094ddd135866e0c | aarch64 | linux | 12+21 | hotspot | jdk | 116.01 MB | urn:net.shipilev.builds | nightly release zgc 7bce94de96e795e2137db8915e7021d0b0da2a71 | aarch64 | linux | 12+21 | hotspot | jdk | 116.01 MB | urn:net.shipilev.builds | nightly release zgc b964c60f4b21b5fb7ab5bcb54e67d6f515fc1880 | aarch64 | linux | 12+21 | hotspot | jdk | 76.79 MB | urn:net.shipilev.builds | nightly slowdebug 5b22a84933715acb1d5169276e6c7521fa306913 | aarch64 | linux | 12+21 | hotspot | jdk | 79.25 MB | urn:net.shipilev.builds | nightly shenandoah slowdebug a5be0c9af101bd34305dfddc97d7df1e61e5416e | arm32-hflt | linux | 12+21 | hotspot | jdk | 70.92 MB | urn:net.shipilev.builds | nightly shenandoah slowdebug 67e74172581ab59f4f000e65aefc4ffb911ce251 | arm32-hflt | linux | 12+21 | hotspot | jdk | 95.62 MB | urn:net.shipilev.builds | fastdebug nightly shenandoah b7cfa6c0a54ce5c8309ec788e81be5b73c5bc54d | arm32-hflt | linux | 12+21 | hotspot | jdk | 95.76 MB | urn:net.shipilev.builds | fastdebug nightly 41622e65270925a1a8a696dbf8d89c12e907d521 | arm32-hflt | linux | 12+21 | hotspot | jdk | 106.06 MB | urn:net.shipilev.builds | nightly release ca5fb73145626725c668439e4fec401b218e70f9 | arm32-hflt | linux | 12+21 | hotspot | jdk | 70.97 MB | urn:net.shipilev.builds | nightly slowdebug 30d584ded81fbf583564bfe5166f0d9e62e1d535 | arm32-hflt | linux | 12+21 | hotspot | jdk | 250.91 MB | urn:net.shipilev.builds | nightly slowdebug 1e3f5090105343b2955007c1ea0427ae9490e6dc | arm32-hflt | linux | 12+21 | hotspot | jdk | 95.64 MB | urn:net.shipilev.builds | fastdebug nightly shenandoah 21ca3b4736eaa4689ccfdcc7cd9366a19958b9ec | arm32-hflt | linux | 12+21 | hotspot | jdk | 305.88 MB | urn:net.shipilev.builds | fastdebug nightly db009a073a939053d68c901063bac086ec65daa4 | arm32-hflt | linux | 12+21 | hotspot | jdk | 154.30 MB | urn:net.shipilev.builds | nightly release add362e2af9be1dff3d3e09f3b749560f54c77c1 | arm32-hflt | linux | 12+21 | hotspot | jdk | 70.93 MB | urn:net.shipilev.builds | nightly shenandoah slowdebug 9440a6662ba6776ac84f31f3d9a2626cdc99dfa8 | arm32-hflt | linux | 12+21 | hotspot | jdk | 105.91 MB | urn:net.shipilev.builds | nightly release shenandoah faf12911c10d7a90d24c8e7d7b2a506107234c04 | arm32-hflt | linux | 12+21 | hotspot | jdk | 105.91 MB | urn:net.shipilev.builds | nightly release shenandoah 8001cc7e39326c2ad90ba7f81b0f2c2f8f4dc41d | ppc64le | linux | 12+21 | hotspot | jdk | 73.12 MB | urn:net.shipilev.builds | nightly shenandoah slowdebug 9ca213b6984e2a59b9a8cbdd15734acb4b83d05c | ppc64le | linux | 12+21 | hotspot | jdk | 107.82 MB | urn:net.shipilev.builds | nightly release 309d7f83aa3f3911559fec2a2db448b0f65c35ec | ppc64le | linux | 12+21 | hotspot | jdk | 101.18 MB | urn:net.shipilev.builds | fastdebug nightly zgc 57dec4a8b440ce20439ae4c60c979adbc1ab18a5 | ppc64le | linux | 12+21 | hotspot | jdk | 107.50 MB | urn:net.shipilev.builds | nightly release zgc 5f58fc923aa14d4a28091182e6070cf84ab25eec | ppc64le | linux | 12+21 | hotspot | jdk | 101.02 MB | urn:net.shipilev.builds | fastdebug nightly shenandoah 1f267dd83d3454cc27909fcb21251b115aa3755c | ppc64le | linux | 12+21 | hotspot | jdk | 107.63 MB | urn:net.shipilev.builds | nightly release shenandoah f1672419cffc73f65991589fc4d2966ab8755f07 | ppc64le | linux | 12+21 | hotspot | jdk | 101.18 MB | urn:net.shipilev.builds | fastdebug nightly zgc e05087155a4cde6201de2849f3c043028fee24a0 | ppc64le | linux | 12+21 | hotspot | jdk | 101.06 MB | urn:net.shipilev.builds | fastdebug nightly eb75e81d9858b4fad890303d14fb13477b2ad819 | ppc64le | linux | 12+21 | hotspot | jdk | 73.11 MB | urn:net.shipilev.builds | nightly slowdebug zgc 2fc657d94df0dfe74f786aa62ca3048aef5892c5 | ppc64le | linux | 12+21 | hotspot | jdk | 257.30 MB | urn:net.shipilev.builds | nightly slowdebug cb0664a9e43b8cc26b8dbdf5d874724f3f7f314e | ppc64le | linux | 12+21 | hotspot | jdk | 73.11 MB | urn:net.shipilev.builds | nightly slowdebug zgc afb0a462f644d2c68408765dd1a692dd001cbbfd | ppc64le | linux | 12+21 | hotspot | jdk | 156.31 MB | urn:net.shipilev.builds | nightly release d7d78ff0162d1251d2a4c5a11bd234c173b0982d | ppc64le | linux | 12+21 | hotspot | jdk | 73.10 MB | urn:net.shipilev.builds | nightly slowdebug abdba847d213b4c84cebc72b1920ddd521f45f9a | ppc64le | linux | 12+21 | hotspot | jdk | 73.12 MB | urn:net.shipilev.builds | nightly shenandoah slowdebug 7344bd9d9d749d70ad58c1111e2ee6a41847d4ac | ppc64le | linux | 12+21 | hotspot | jdk | 101.02 MB | urn:net.shipilev.builds | fastdebug nightly shenandoah 104ba8c7b56d0256716abff98ec74b3e10253a9b | ppc64le | linux | 12+21 | hotspot | jdk | 322.07 MB | urn:net.shipilev.builds | fastdebug nightly 1fca94fcf26db7db1896cf4caf48a82b2dd4e7ec | ppc64le | linux | 12+21 | hotspot | jdk | 107.63 MB | urn:net.shipilev.builds | nightly release shenandoah 05f59d96b70ddd546f4aed9c54ddc722ad07a44c | ppc64le | linux | 12+21 | hotspot | jdk | 107.50 MB | urn:net.shipilev.builds | nightly release zgc c24fa177beb636bc4043709051e1a53a600ebeaf | s390x | linux | 12+21 | hotspot | jdk | 105.45 MB | urn:net.shipilev.builds | nightly release 9cf0e943adfc9f186437a4b9162fc9d3578b951b | s390x | linux | 12+21 | hotspot | jdk | 152.38 MB | urn:net.shipilev.builds | nightly release 034582f7d1a49e3067770dfd6eec54bac34f376c | s390x | linux | 12+21 | hotspot | jdk | 98.23 MB | urn:net.shipilev.builds | fastdebug nightly shenandoah e784339a639620f422ef6bab3ba0360e2e3e73c0 | s390x | linux | 12+21 | hotspot | jdk | 105.29 MB | urn:net.shipilev.builds | nightly release shenandoah e996a57c6e86892f3b53a293b0769ec2708de9c2 | s390x | linux | 12+21 | hotspot | jdk | 75.01 MB | urn:net.shipilev.builds | nightly slowdebug bd2490e07483fe4dc6df4a43f4d55a1348995743 | s390x | linux | 12+21 | hotspot | jdk | 105.30 MB | urn:net.shipilev.builds | nightly release shenandoah 946ed299ababd8560768910e90b1bf75df296b08 | s390x | linux | 12+21 | hotspot | jdk | 264.21 MB | urn:net.shipilev.builds | nightly slowdebug bcacf4f5e8708394e11e331d43c79cde232d84c9 | s390x | linux | 12+21 | hotspot | jdk | 74.93 MB | urn:net.shipilev.builds | nightly shenandoah slowdebug 7b8c02f653a0ee3256a1e30223e30bd43cac16ec | s390x | linux | 12+21 | hotspot | jdk | 74.93 MB | urn:net.shipilev.builds | nightly shenandoah slowdebug fdfd03951755776c5db961f4dc1ec60e65843045 | s390x | linux | 12+21 | hotspot | jdk | 98.23 MB | urn:net.shipilev.builds | fastdebug nightly shenandoah 62124b09185f58c3b6f2d50948979a36b187eaf0 | s390x | linux | 12+21 | hotspot | jdk | 98.27 MB | urn:net.shipilev.builds | fastdebug nightly 402783861b1e81dbc202363e5498732adb8ba579 | s390x | linux | 12+21 | hotspot | jdk | 319.23 MB | urn:net.shipilev.builds | fastdebug nightly e58528f487d5f482b15d585dcacd3c9629a88a5c | x32 | linux | 12+21 | hotspot | jdk | 78.63 MB | urn:net.shipilev.builds | nightly shenandoah slowdebug 2c0d6c37670ee24604f6c7f8a5f98400e950a88e | x32 | linux | 12+21 | hotspot | jdk | 78.63 MB | urn:net.shipilev.builds | nightly shenandoah slowdebug 101b3c93f013bae3efcede5fa9310b9af5bc5fc4 | x32 | linux | 12+21 | hotspot | jdk | 100.89 MB | urn:net.shipilev.builds | fastdebug nightly baca17de2f8610d24b6a7c8776097ee892c5e29d | x32 | linux | 12+21 | hotspot | jdk | 266.56 MB | urn:net.shipilev.builds | nightly slowdebug 1dcf07ede6ae50d1d61eeeb5110dd3b0fd70232d | x32 | linux | 12+21 | hotspot | jdk | 157.08 MB | urn:net.shipilev.builds | nightly release 38dc2e007077d591f46967924c1b71f290c350bd | x32 | linux | 12+21 | hotspot | jdk | 105.91 MB | urn:net.shipilev.builds | fastdebug nightly shenandoah a13d4a7609b853e313b22fefe59d10cb9453460d | x32 | linux | 12+21 | hotspot | jdk | 109.11 MB | urn:net.shipilev.builds | nightly release shenandoah 6a754e756eb7b580e1569f5d653dbd75f90b167c | x32 | linux | 12+21 | hotspot | jdk | 108.71 MB | urn:net.shipilev.builds | nightly release 1311873abaf6ee8c9c0e39a5dd350d87f95cd4bb | x32 | linux | 12+21 | hotspot | jdk | 76.19 MB | urn:net.shipilev.builds | nightly slowdebug 89103696a64b2672c83562fc8e6d9212a6d9088a | x32 | linux | 12+21 | hotspot | jdk | 109.11 MB | urn:net.shipilev.builds | nightly release shenandoah 55ce34bcdd6c52d64e1c4f55738eabf68a392306 | x32 | linux | 12+21 | hotspot | jdk | 322.27 MB | urn:net.shipilev.builds | fastdebug nightly be3085029dcc7a570c6dbda09ff8c4ccce3ad974 | x32 | linux | 12+21 | hotspot | jdk | 105.92 MB | urn:net.shipilev.builds | fastdebug nightly shenandoah 46191f013fd6f2ad933bfaec560b5927dbac2f72 | x64 | linux | 12+21 | hotspot | jdk | 122.87 MB | urn:net.shipilev.builds | fastdebug nightly zgc 8ceeb1cf23de4e2268c0f195363998508577a50b | x64 | linux | 12+21 | hotspot | jdk | 123.40 MB | urn:net.shipilev.builds | nightly release zgc a8dc8e9bf881e768be61bbca115ef52a543b87b0 | x64 | linux | 12+21 | hotspot | jdk | 89.48 MB | urn:net.shipilev.builds | loom nightly slowdebug cccf24287365606b8120c43d2fa7b6cf3e830072 | x64 | linux | 12+21 | hotspot | jdk | 123.41 MB | urn:net.shipilev.builds | nightly release zgc f8d7c8653c936bde5f0ec99fdf91975ec951fc88 | x64 | linux | 12+21 | hotspot | jdk | 89.12 MB | urn:net.shipilev.builds | nightly slowdebug zgc 8997d72aeccb14610c2e74c7a766ca28f262a828 | x64 | linux | 12+21 | hotspot | jdk | 89.13 MB | urn:net.shipilev.builds | nightly slowdebug zgc 37fd186be5781152eeae5862feaa9ee54a7d985a | x64 | linux | 12+21 | hotspot | jdk | 124.30 MB | urn:net.shipilev.builds | nightly release shenandoah ef6219fae585243ecca7735dc2482cdabccc559c | x64 | linux | 12+21 | hotspot | jdk | 302.38 MB | urn:net.shipilev.builds | nightly slowdebug 9e702a1dcc96f6a02c1622f2bc5c7f5975ecc58f | x64 | linux | 12+21 | hotspot | jdk | 91.91 MB | urn:net.shipilev.builds | nightly shenandoah slowdebug ca757f348952c504f5a88e3c5b462be853c130f3 | x64 | linux | 12+21 | hotspot | jdk | 123.71 MB | urn:net.shipilev.builds | nightly release 058d0a8f765a74418309541ca1b9eb4f21880718 | x64 | linux | 12+21 | hotspot | jdk | 88.93 MB | urn:net.shipilev.builds | nightly slowdebug 9717cd9993ef98c7f8e11e9c5f8afd231b59531c | x64 | linux | 12+21 | hotspot | jdk | 129.18 MB | urn:net.shipilev.builds | fastdebug nightly shenandoah 215871aa40df935b3e2f428c4ef91b600071e4ad | x64 | linux | 12+21 | hotspot | jdk | 129.17 MB | urn:net.shipilev.builds | fastdebug nightly shenandoah 716b372d8c0ceae9b97b486b98a83fb6d3f6d0b2 | x64 | linux | 12+21 | hotspot | jdk | 122.86 MB | urn:net.shipilev.builds | fastdebug nightly zgc 4f58887133e0577e711332368d90b3fad4514156 | x64 | linux | 12+21 | hotspot | jdk | 123.73 MB | urn:net.shipilev.builds | loom nightly release 8a86b4d7e128872038069c8b9948a975b3c577a6 | x64 | linux | 12+21 | hotspot | jdk | 377.94 MB | urn:net.shipilev.builds | fastdebug nightly 6f7d6c1269e00ba7186a6fbd24056c244e42fb35 | x64 | linux | 12+21 | hotspot | jdk | 124.30 MB | urn:net.shipilev.builds | nightly release shenandoah 119303d7130d42c048502745e8a3d7e0710d17b8 | x64 | linux | 12+21 | hotspot | jdk | 91.92 MB | urn:net.shipilev.builds | nightly shenandoah slowdebug 4d4b9fda3681ca911c015a05b48bc0e3e964e9f0 | x64 | linux | 12+21 | hotspot | jdk | 122.66 MB | urn:net.shipilev.builds | fastdebug nightly f693ac944176ce4351d44356c32d1fe66613e900 | x64 | linux | 12+21 | hotspot | jdk | 176.80 MB | urn:net.shipilev.builds | nightly release 9c8be5a107ec2f7b2075aedce863d802bef3ed74 | x64 | windows | 12+21 | hotspot | jdk | 73.96 MB | urn:net.shipilev.builds | nightly shenandoah slowdebug 9fbf055805d4d5767e5e1a06e200c09c1e40288c | x64 | windows | 12+21 | hotspot | jdk | 184.56 MB | urn:net.shipilev.builds | nightly release zgc 32cde4bbe4af9623af19833663ac68a4c59e6e86 | x64 | windows | 12+21 | hotspot | jdk | 0.00 MB | urn:net.shipilev.builds | fastdebug loom nightly 29d1cf3b48a16c35f00b62052b7b9ee684e6acde | x64 | windows | 12+21 | hotspot | jdk | 240.33 MB | urn:net.shipilev.builds | nightly release 8badae50d2e782ccd023c9abbee606febd67e9b3 | x64 | windows | 12+21 | hotspot | jdk | 73.70 MB | urn:net.shipilev.builds | fastdebug nightly zgc beca288685a5f3c077dfb5d79f960c456017a558 | x64 | windows | 12+21 | hotspot | jdk | 0.00 MB | urn:net.shipilev.builds | loom nightly release 948b5248ea66c1e376ddff4e878b2315b6ce2e5b | x64 | windows | 12+21 | hotspot | jdk | 205.90 MB | urn:net.shipilev.builds | fastdebug nightly 29384ff9b699b7d8d8675ca521bc457ecc953ae8 | x64 | windows | 12+21 | hotspot | jdk | 73.60 MB | urn:net.shipilev.builds | nightly slowdebug zgc 42c5e89cbffe1bad79efcf7ea90e654e5fcecb83 | x64 | windows | 12+21 | hotspot | jdk | 189.06 MB | urn:net.shipilev.builds | nightly release shenandoah 2ef36f7bb3856ee92e2080accb186c639961b330 | x64 | windows | 12+21 | hotspot | jdk | 0.00 MB | urn:net.shipilev.builds | loom nightly slowdebug 450217456d789a9508e706098f74162dfab73e93 | x64 | windows | 12+21 | hotspot | jdk | 74.09 MB | urn:net.shipilev.builds | fastdebug nightly shenandoah c4828da3ed447e7046000dc467d68b44430ee72b | aarch64 | linux | 12+22 | hotspot | jdk | 105.47 MB | urn:net.shipilev.builds | fastdebug nightly daa855eaaf2b40ae6e3f34d7d01793857c66aecc | aarch64 | linux | 12+22 | hotspot | jdk | 116.07 MB | urn:net.shipilev.builds | nightly release fa11c1973f987aa8d1923e8c23c8b539044e0d6b | aarch64 | linux | 12+22 | hotspot | jdk | 76.78 MB | urn:net.shipilev.builds | nightly slowdebug 20bea8ab498eb71e2984080895740c84995d3ea8 | aarch64 | linux | 12+22 | hotspot | jdk | 116.08 MB | urn:net.shipilev.builds | nightly release d99ad721c511248f985c272c6f914c55165d20c9 | aarch64 | linux | 12+22 | hotspot | jdk | 105.47 MB | urn:net.shipilev.builds | fastdebug nightly abfb427010e0e79ee4f2ad7785e126c53869584b | aarch64 | linux | 12+22 | hotspot | jdk | 76.77 MB | urn:net.shipilev.builds | nightly slowdebug ade576f034a7608b69be5c95b77a28d98a986822 | arm32-hflt | linux | 12+22 | hotspot | jdk | 105.89 MB | urn:net.shipilev.builds | nightly release 2dbab8e9d43cd02852076dba034ec1f09df09565 | arm32-hflt | linux | 12+22 | hotspot | jdk | 105.89 MB | urn:net.shipilev.builds | nightly release 63fd16add4a56597ea11bdeb3d46cc841f480fa0 | arm32-hflt | linux | 12+22 | hotspot | jdk | 70.91 MB | urn:net.shipilev.builds | nightly slowdebug e2336c0905eaaf36921bdd69fe1f36c8c7a37328 | arm32-hflt | linux | 12+22 | hotspot | jdk | 95.63 MB | urn:net.shipilev.builds | fastdebug nightly 4ead3442d37850050b9a7eb5e270a16373db7fa1 | arm32-hflt | linux | 12+22 | hotspot | jdk | 95.63 MB | urn:net.shipilev.builds | fastdebug nightly edbc20db468b286c9fe9cfbdb071e9174e8c597a | arm32-hflt | linux | 12+22 | hotspot | jdk | 70.91 MB | urn:net.shipilev.builds | nightly slowdebug 8832b45a9778af07bf411a235b267e71d2740a45 | ppc64le | linux | 12+22 | hotspot | jdk | 101.05 MB | urn:net.shipilev.builds | fastdebug nightly cb16f5f55b578bc5c8317c9458443752f33f61f9 | ppc64le | linux | 12+22 | hotspot | jdk | 101.06 MB | urn:net.shipilev.builds | fastdebug nightly d85ae765bfb08882d534b31c6dc0f5d2eebd287d | ppc64le | linux | 12+22 | hotspot | jdk | 73.09 MB | urn:net.shipilev.builds | nightly slowdebug deffdd0a4ac6c31ba93f8af8be60f4a2e405f0cf | ppc64le | linux | 12+22 | hotspot | jdk | 73.04 MB | urn:net.shipilev.builds | nightly slowdebug b1fea013f575e060197d3fdf03d3d5ece70f29b2 | ppc64le | linux | 12+22 | hotspot | jdk | 107.58 MB | urn:net.shipilev.builds | nightly release f9a0711959cc2c3aa551174229fcdb6a8214966a | ppc64le | linux | 12+22 | hotspot | jdk | 107.59 MB | urn:net.shipilev.builds | nightly release 11fc3c55e8c402ef283e37cb9d17b22cf15d7e8a | s390x | linux | 12+22 | hotspot | jdk | 74.93 MB | urn:net.shipilev.builds | nightly slowdebug 5bc8eb499eeccd85958b97feb000d4628001bb17 | s390x | linux | 12+22 | hotspot | jdk | 98.27 MB | urn:net.shipilev.builds | fastdebug nightly 91cda32d77b6e393438e06ae2e1b2118b5d84c9b | s390x | linux | 12+22 | hotspot | jdk | 74.92 MB | urn:net.shipilev.builds | nightly slowdebug f1036a7750c38a8b968f6e9e18f11f9204c31217 | s390x | linux | 12+22 | hotspot | jdk | 105.26 MB | urn:net.shipilev.builds | nightly release 14a4ea6969efbbc04253f7e22d7c0120b96031b5 | s390x | linux | 12+22 | hotspot | jdk | 105.27 MB | urn:net.shipilev.builds | nightly release 0df043bbfa95203e85b612170f52f8454db7de8f | s390x | linux | 12+22 | hotspot | jdk | 98.27 MB | urn:net.shipilev.builds | fastdebug nightly cdd533589be7e38f87d4e98a97587c73cd73c1b5 | x32 | linux | 12+22 | hotspot | jdk | 100.85 MB | urn:net.shipilev.builds | fastdebug nightly 5f9cec29fa4f2c93f157cc2640c2981b4a69440c | x32 | linux | 12+22 | hotspot | jdk | 76.11 MB | urn:net.shipilev.builds | nightly slowdebug ff71f742221c502896f8bad84ad3729aab48c367 | x32 | linux | 12+22 | hotspot | jdk | 108.51 MB | urn:net.shipilev.builds | nightly release 0f479807949d04a7af905c6ae81f2b4e036d9175 | x32 | linux | 12+22 | hotspot | jdk | 76.14 MB | urn:net.shipilev.builds | nightly slowdebug 1703f27550bd19944f34413a0f2e45bb66d06eab | x32 | linux | 12+22 | hotspot | jdk | 100.85 MB | urn:net.shipilev.builds | fastdebug nightly 6d6b52663c3f9573d3c9d0c8bab700b3cb9c5e1e | x32 | linux | 12+22 | hotspot | jdk | 108.51 MB | urn:net.shipilev.builds | nightly release 930431b22fc11f6c025b1ca3bfe9d05bc266ae5a | x64 | linux | 12+22 | hotspot | jdk | 88.94 MB | urn:net.shipilev.builds | nightly slowdebug 6ec8da134510d02a7f9a33c8ce4bef1892b087c4 | x64 | linux | 12+22 | hotspot | jdk | 88.89 MB | urn:net.shipilev.builds | nightly slowdebug 02e57db05c0d922a967646a5704a347f3a5585bc | x64 | linux | 12+22 | hotspot | jdk | 123.50 MB | urn:net.shipilev.builds | nightly release d9e0cdbc7681b46a83cfb2744fa9e0fc37c2cbf9 | x64 | linux | 12+22 | hotspot | jdk | 123.49 MB | urn:net.shipilev.builds | nightly release dc92b0c4108f2d451c2d91d382d89a98bde38609 | x64 | linux | 12+22 | hotspot | jdk | 122.63 MB | urn:net.shipilev.builds | fastdebug nightly d8ae2e75adca53ba039f814029a823d3b605fe46 | x64 | linux | 12+22 | hotspot | jdk | 122.61 MB | urn:net.shipilev.builds | fastdebug nightly 68d8667ef7cc5fa6c37c1cd6c061f38f41a4ebb9 | x64 | windows | 12+22 | hotspot | jdk | 184.55 MB | urn:net.shipilev.builds | nightly release 75bd2660224ccde06c14989cf6dc260cd561d930 | x64 | windows | 12+22 | hotspot | jdk | 73.60 MB | urn:net.shipilev.builds | nightly slowdebug 2d8be6d22c8e0d28a2f495eb50cfc44f9da15420 | x64 | windows | 12+22 | hotspot | jdk | 73.71 MB | urn:net.shipilev.builds | fastdebug nightly [coffeepick]$ download 2d8be6d22c8e0d28a2f495eb50cfc44f9da15420 [ 5.20 MB / 73.71 MB] |+++++ | 5.20MB/s [ 10.59 MB / 73.71 MB] |+++++++++ | 5.39MB/s [ 15.93 MB / 73.71 MB] |+++++++++++++ | 5.34MB/s [ 21.11 MB / 73.71 MB] |++++++++++++++++++ | 5.18MB/s [ 24.51 MB / 73.71 MB] |++++++++++++++++++++ | 3.41MB/s [ 28.25 MB / 73.71 MB] |+++++++++++++++++++++++ | 3.74MB/s [ 32.54 MB / 73.71 MB] |+++++++++++++++++++++++++++ | 4.29MB/s [ 36.15 MB / 73.71 MB] |++++++++++++++++++++++++++++++ | 3.60MB/s [ 40.32 MB / 73.71 MB] |+++++++++++++++++++++++++++++++++ | 4.18MB/s [ 45.22 MB / 73.71 MB] |+++++++++++++++++++++++++++++++++++++ | 4.90MB/s [ 50.30 MB / 73.71 MB] |+++++++++++++++++++++++++++++++++++++++++ | 5.08MB/s [ 53.58 MB / 73.71 MB] |++++++++++++++++++++++++++++++++++++++++++++ | 3.28MB/s [ 58.12 MB / 73.71 MB] |++++++++++++++++++++++++++++++++++++++++++++++++ | 4.54MB/s [ 62.97 MB / 73.71 MB] |++++++++++++++++++++++++++++++++++++++++++++++++++++ | 4.85MB/s [ 66.97 MB / 73.71 MB] |+++++++++++++++++++++++++++++++++++++++++++++++++++++++ | 4.00MB/s [ 70.62 MB / 73.71 MB] |++++++++++++++++++++++++++++++++++++++++++++++++++++++++++ | 3.66MB/s Download finished Runtime archive: /home/rm/local/coffeepick/inventory/2d8be6d22c8e0d28a2f495eb50cfc44f9da15420/archive
In his own words:
... the binaries there are very volatile by nature, many rotate daily, so hooking them up to something more or less permanent would be problematic.
Expect to have to run repository-update urn:net.shipilev.builds
every day if you use the repository!