I've recently been looking into the allocation of device memory in Vulkan. It turns out there's a lot of complexity around balancing the various constraints that the API imposes.
Device Memory
Vulkan has the concepts of device memory and host memory. Host memory is the common memory that developers are accustomed to: It's the memory that is accessed and controlled by the host CPU on the current machine, and the memory that is returned by malloc() and friends. We won't talk much about host memory here, because there's nothing new or interesting to say about it, and it works the same way in Vulkan as in regular programming environments.
Device memory, on the other hand, is memory that is directly accessible to whatever the GPU is on the current system. Device memory is exposed to the Vulkan programmer via a number of independent heaps. For example, on a system (at the time of writing) with an AMD Radeon RX 5700 GPU, device memory is exposed as three different heaps:
- An 8gb heap of "device local" memory. This is 8gb of GDDR6 soldered directly to the card.
- A portion of the host system's RAM exposed to the GPU. On my workstation with 32gb of RAM, the GPU is provided with a 16gb heap of system memory.
- A small 256mb heap that is directly accessible to both the GPU and the host system (more on this later).
The different heaps have different performance characteristics and different capabilities. For example, some heaps can be directly memory-mapped for reading and writing by the host computer using the vkMapMemory function (similar to the POSIX mmap function). Some heaps are solely and directly accessible to the GPU and therefore are the fastest memory for the GPU to read and write. In order for the host CPU to read and write this memory, explicit transfer commands must be executed using the Vulkan API. Reads and writes to memory that is not directly connected to the GPU must typically go over the PCI bus, and are therefore slower than reads and writes to directly GPU-connected memory in relative terms.
Naturally, different types of GPU expose different sets of heaps. On systems with GPUs integrated into the CPU, there might only be a single heap. For example, on a fairly elderly laptop with an Intel HD 620 embedded GPU, there is simply one 12gb heap that is directly accessible by both the GPU and host CPU.
Vulkan also introduces the concept of memory types. A memory type is a rather vague concept, but it can be considered as a kind of access method for memory in a given heap. For example, a memory type for a given heap might advertise that it can be memory-mapped directly from the host CPU. A different memory type might advertise that there's CPU-side caching of the memory. Another memory type might advertise that it is incoherent, and therefore requires explicit flush operations in order to make any writes to the memory visible to the GPU.
Implementations might require that certain types of GPU resources be allocated in heaps using specific memory types. For example, some NVIDIA GPUs strictly separate memory allocations made to hold color images, allocations made to hold arrays of structured data, and so on. These memory type requirements can exist even when allocations of different types are being made to the same heap.
As mentioned earlier, differing performance characteristics between heaps means
that developers will want to place different kinds of resources in different
heaps in order to take advantage of the properties of each heap. For example, if
the programmer knows that a given texture is immutable, and that it will be
loaded from disk once and then sampled repeatedly by the GPU when rendering,
then it makes sense for this texture to be placed into the fastest, directly
GPU-connected memory. On the other hand, consider what happens if a developer
knows that the contents of a texture are mutable and will be updated on every
frame: In one manner or another, the contents of that texture are almost
certainly going to traverse the PCI bus each time it is updated (assuming a
discrete GPU with a separate device-local heap). Therefore,
it makes sense for that texture to be allocated in a heap that is directly
CPU-accessible and have the GPU read from that memory as needed. Directly
GPU-connected memory tends to be somewhat of a more precious and less abundant
resource, so there's little to be gained by wasting it on a texture that will
need to be transferred anew to the GPU on every frame anyway! The small
256mb heap mentioned at the start of this article is explicitly intended
for those kinds of transfers: The CPU can quickly write data into that heap
and then instruct Vulkan to perform a transfer from that heap into the main
device-local heap. This is essentially a heap for
staging buffers.
Allocation
When allocating a resource, the developer must ask the Vulkan API what the memory requirements will be for the given resource. Essentially, the conversation goes like this:
Developer: I want to create a 256x256 RGBA8 texture, and I want the texture to be laid out in the most optimal form for fast access by the GPU. What are the memory requirements for this data?
Vulkan: You will need to allocate 262144 bytes of memory for this texture, using memory type
T, and the allocated memory must be aligned to a 65536 byte boundary.
The blissfully unaware developer then calls vkAllocateMemory,
passing it a memory size of 262144 and a memory type T. The specification
for vkAllocateMemory actually guarantees that whatever memory it returns will
always obey the alignment restrictions for any kind of resource possible, so
the developer doesn't need to worry about the 65536 byte alignment restriction
above.
This all works fine for a while, but after having allocated a hundred or so
textures like this, suddenly vkAllocateMemory returns VK_ERROR_OUT_OF_DEVICE_MEMORY.
The developer immediately starts doubting their own sanity; after all, their
GPU has a 8gb heap, and they've only allocated about ~26mb of textures. What's
gone wrong?
Well, Vulkan imposes a limit on the number of active allocations that can exist
at any give time. This is advertised to the developer in the
maxMemoryAllocationCount field of the VkPhysicalDeviceLimits
structure returned by the vkGetPhysicalDeviceProperties
function. The Vulkan specification guarantees that this limit will be at least
4096, although it does give a laundry list of reasons why the limit in practice
might be lower. In fact, in some situations, the limit can be much
lower than this. To quote the Vulkan specification for vkAllocateMemory:
As a guideline, the Vulkan conformance test suite requires that at least 80 minimum-size allocations can exist concurrently when no other uses of protected memory are active in the system.
In practical terms, this means that Vulkan developers are required to ask for a small number of large chunks of memory, and then manually sub-allocate that memory for use with resources. This is where the real complexity begins.
Sub-Allocation Constraints
There are a practically unlimited number of possible ways to manage memory, and there are entire books on the subject. Vulkan developers wishing to sub-allocate memory must come up with algorithms that balance at least the following (often contradictory) requirements:
- A fixed-size heap must be divided up into separate allocations with at least one allocation for each memory type that will be used by the application. It's not possible to know which memory type a Vulkan implementation will need for each kind of resource in the application, and it's also not possible to know (without relying on hardware-specific information ahead of time) what kind of heaps will be available, so the heap divisions cannot be decided statically.
- A fixed-size heap must be divided up into as small a number of separate
allocations as possible, in order to stay below the
maxMemoryAllocationCountlimit forvkAllocateMemory. - A fixed-size heap must be divided up into separate allocations where each
allocation is not larger than an implementation-defined limit. The developer
must examine the
maxMemoryAllocationSizeof the VkPhysicalDeviceMaintenance3Properties structure returned by the vkGetPhysicalDeviceProperties2 function. - Developers must obey alignment restrictions themselves. The
vkAllocateMemoryfunction is guaranteed to return memory that is suitably aligned for any possible resource, but developers sub-allocating from one of these allocations must ensure that they place resources at correctly-aligned offsets relative to the start of that allocation. - Fast GPU memory can be in relatively short supply; it's important that as little of it is wasted as possible. Allocation schemes that result in a high degree of memory fragmentation are unsuitable, as this will result in a lot of precious GPU memory becoming unusable.
- There are often soft-realtime constraints. If a rendering operation of some kind needs memory right now, and there's a deadline of 16ms of rendering time in order to meet a 60hz frame rate, an allocation algorithm that takes a second or two to find free memory is unusable.
- Sub-allocations must consist of contiguous memory. There is no way to
have, for example, a single texture use memory from multiple disjoint
regions of memory. It follows that each
allocation must be at least large enough to hold resources of the expected size.
For example, on most platforms, allocating a
4096x1024 RGBA8texture will require roughly16mbof storage. If we divide the heap up into allocations no larger than8mb, we will never be able to store a texture of this size.
Edit: Textures and buffers can use non-contiguous memory via sparse resources. Support for this cannot be relied upon.
It is fairly difficult to come up with memory allocation algorithms that will meet all of these requirements.
Developers are expected to use large allocations in order to stay below the
limit on the number of active allocations imposed by vkAllocateMemory, but
at the same time they can't use allocations that are too large and would
exceed the maxMemoryAllocationSize limit. Developers don't know what sizes
and types of heaps they will be presented with, so allocation sizes must be
decided by educated guesses and heuristics, and probing the heap sizes at
application startup.
In order to obey alignment restrictions, reduce memory fragmentation and avoid wasting too much memory by having unused space between aligned objects, it's almost certainly necessary to bucket sub-allocations by size, and place them into separate regions of memory. If this bucketing is not performed, then large numbers of small sub-allocations within an allocation can result in there not being enough contiguous space for a larger sub-allocation, even if there is otherwise enough non-contiguous free space for it.
How should sub-allocations be bucketed, though? The Vulkan specification does provide some guarantees as to what the returned alignment restrictions will be, not limited to:
The alignment member is a power of two.
If usage included VK_BUFFER_USAGE_STORAGE_BUFFER_BIT, alignment must be an integer multiple of VkPhysicalDeviceLimits::minStorageBufferOffsetAlignment.
However, the alignment requirements can vary wildly between platforms. As
an example, I wrote a small program that tried asking for the memory
requirements for an RGBA8 texture in every combination of power-of-two
sizes up to a maximum of 4096 (the largest texture width/height guaranteed to
be supported by all Vulkan implementations). I specifically asked for textures
using the tiling type VK_IMAGE_TILING_OPTIMAL as there is very little reason
to use the discouraged VK_IMAGE_TILING_LINEAR. Use of VK_IMAGE_TILING_LINEAR
can relax storage/alignment restrictions at the cost of much slower rendering
performance.
I ran the program on a selection of platforms:
LinuxIntelMesa: Linux, Intel(R) HD Graphics 620, Mesa driverLinuxAMDRADV: Linux, AMD Radeon RX 5700, RADV driverWindowsAMDProp: Windows, AMD Integrated, proprietary driverWindowsNVIDIAProp: Windows, NVIDIA GeForce GTX 1660 Ti, proprietary driver
The following graph shows the alignment requirements for every image size on every driver (click for full-size image):

Some observations can be made from this data:
- On the
LinuxIntelMesaplatform, the required alignment for image data is always4096. This is almost certainly something to do with the fact that the GPU is integrated with the CPU, and simply expects image data to be aligned to the native page size of the platform. - On the
WindowsNVIDIAPropplatform, the required alignment for image data is always1024. - On the
LinuxAMDRADVplatform, the required alignment for image data is either4096or65536. Strangely, there appears to be no clear relation that explains why an image might require65536byte alignment instead of4096byte alignment. The first image size to require65536byte alignment is128x128, which coincidentally requires65536bytes of storage. However, a smaller image size such as256x64also requires65536bytes of storage, but only has a reported alignment requirement of4096bytes. - The
WindowsAMDPropplatform behaves similarly to theLinuxAMDRADVplatform except that it often allows for a smaller alignment of256bytes. Even some very large images such as16x4096can require a256byte alignment. - These platforms do, at least, tend to stick to a very small set of alignment values.
Similarly, the data for the storage requirements for each size of image (click for full-size image):

Some observations can be made from this data:
- Images of the exact same size and format can take different amounts of
space on different platforms. A
128x16image using4bytes per pixel should theoretically take128 * 16 * 4 = 8192bytes of storage space, but it actually requires20504,16384, or8192bytes depending on the target platform. - All platforms seem to have some minimum storage size, such that even microscopic
images will require a minimum amount of storage. This suggests some kind of
internal block or page-based allocation scheme in the hardware.
On
LinuxIntelMesa, images will always consume at least8126bytes. OnLinuxAMDRADV, images will always consume at least4096bytes. OnWindowsNVIDIAProp, images will always consume at least512bytes. OnWindowsAMDProp, images will always consume at least256bytes. - Frequently, images with similar values on one dimension will require the
same amount of storage. For example,
2x4096and4x4096sized images require the same amount of storage on all surveyed platforms. This is true for some platforms all the way up to64x4096! - On
LinuxIntelMesa, storage sizes vary a lot, and are often not powers of two. On the other platforms, storage sizes are always a power of two.
The raw datasets are available:
- image-sizes-linux-intel.txt
- image-sizes-radv-linux.txt
- image-sizes-windows-amd.txt
- image-sizes-windows-nvidia.txt
- gpu-align.txt
- gpu-size.txt
With all of this data, it suffices to say that it is not possible for an allocator to use any kind of statically-determined, platform-independent size-based bucketing policy; the storage and alignment requirements for any given image differ wildly across platforms and seem to bear very little relation to the dimensions of the images.
However, textures are fairly complex in the sense of having lots of different properties such as format, number of layers, number of mipmaps, tiling mode, etc. We know that most GPUs have hardware specifically dedicated to texture operations, and so we can infer that a lot of the odd storage and alignment restrictions might be due to the idiosyncrasies of that hardware.
Vulkan developers also work with buffers, which can more or less be thought
of as arrays that live in device memory. Do buffers also have the same storage
and alignment oddities in practice? I wrote another program that requests
memory requirements for a range of different sizes of buffer and ran it
on the set of platforms above. I requested a buffer with a usage of
type VK_BUFFER_USAGE_STORAGE_BUFFER_BIT, although trying different usage
flags didn't seem to change the numbers returned on any platform, so we can
probably assume that the values will be fairly consistent for all usage flags.
The following graph shows the alignment requirements for a range of buffer sizes on every driver (click for full-size image):
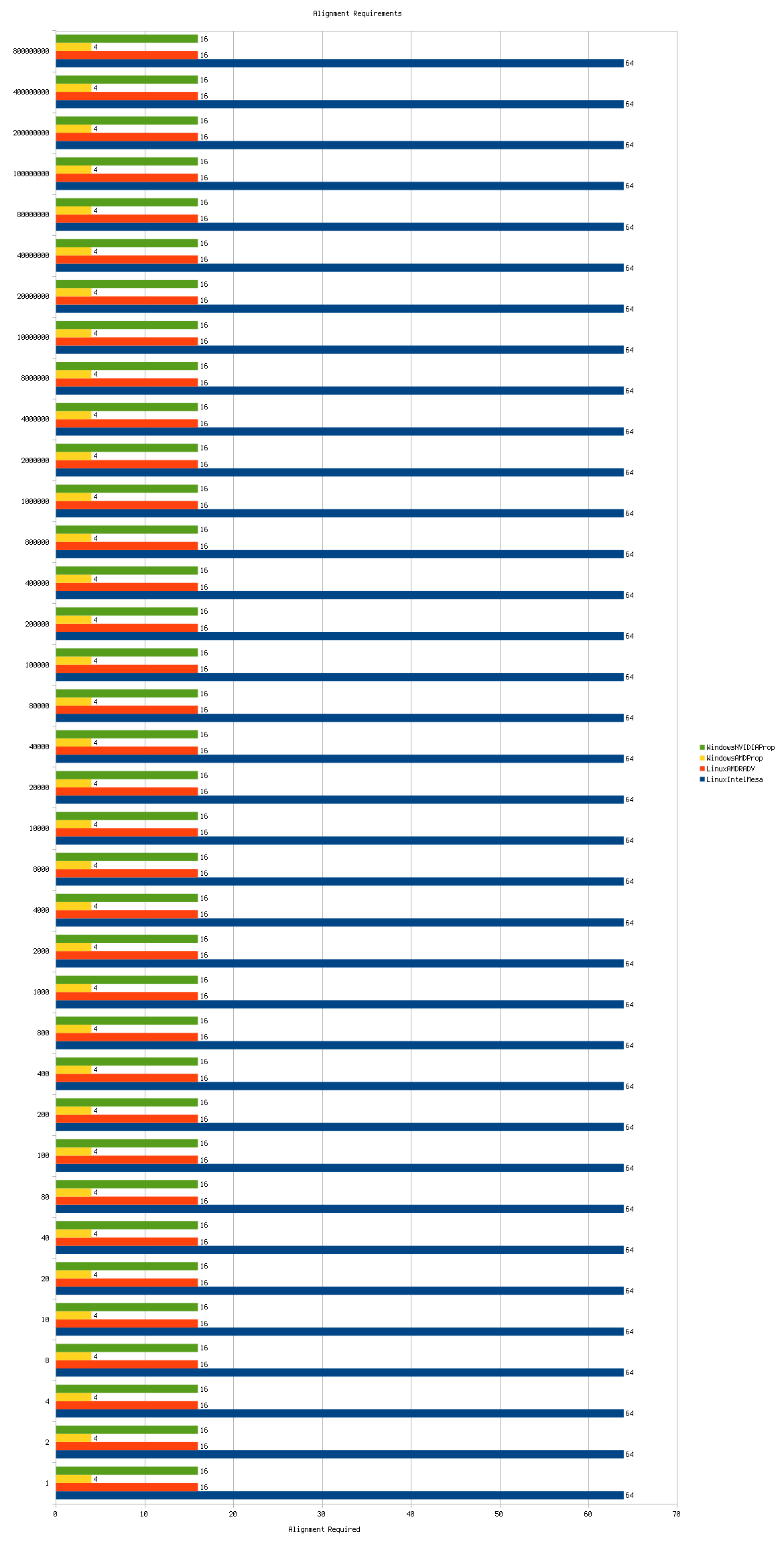
Only one observation can be made from this data:
- The alignment requirements appear to be fixed on each platform and are irrespective of the requested buffer size.
The following graph shows the storage requirements for a range of buffer sizes on every driver (click for full-size image):
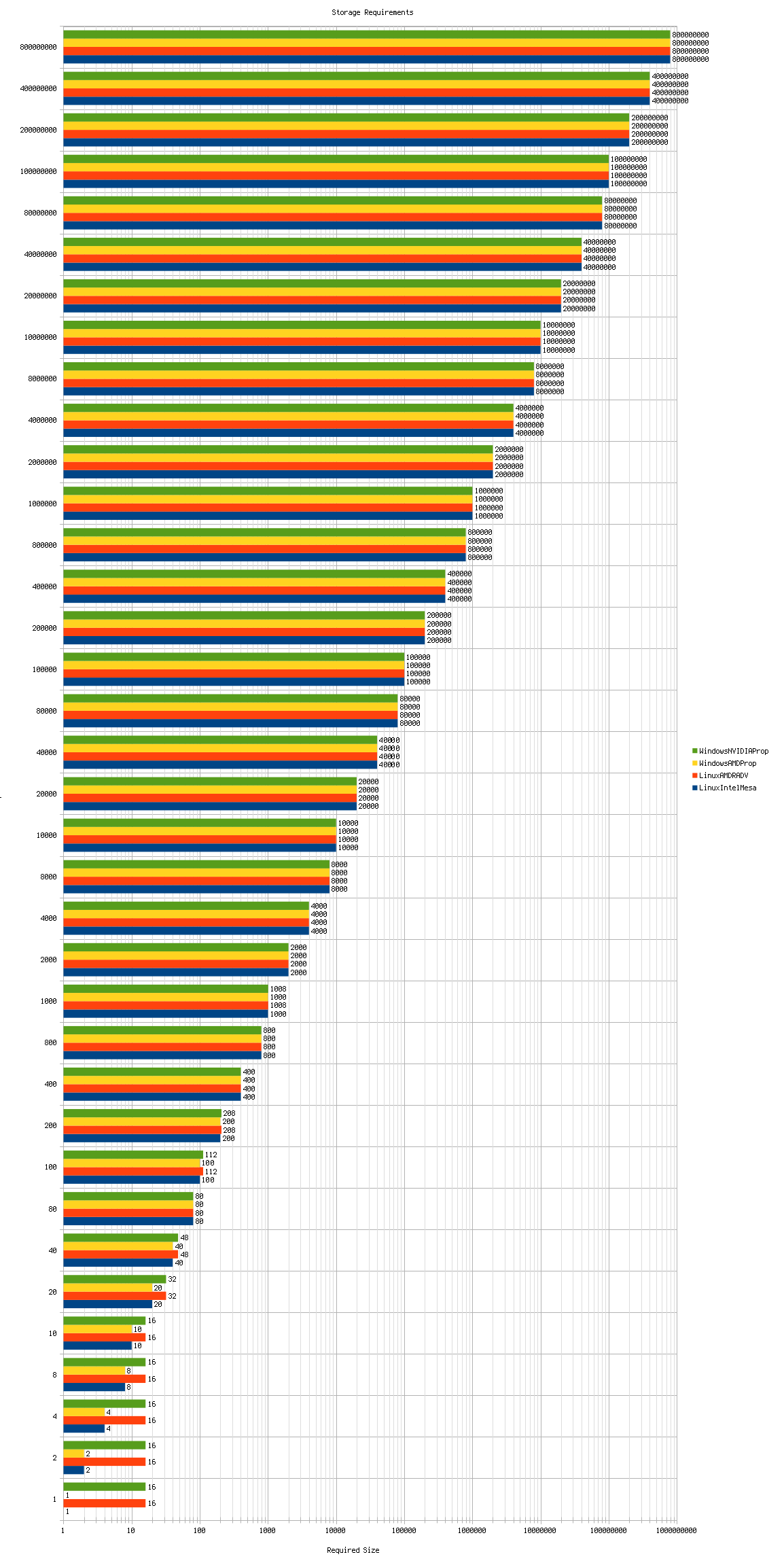
Some observations can be made from this data:
- On all platforms, for buffers larger than about 32 bytes, the storage size required for a given buffer is typically within about eight bytes of the original requested size.
- On
LinuxAMDRADVandWindowsNVIDIAProp, requesting a buffer of less than16bytes simply results in an allocation of16bytes. - For buffers larger than about
1000bytes (the threshold will almost certainly turn out to be1024), the required storage size is exactly equal to the requested buffer size.
The raw datasets are available:
- gpu-buffer-align.txt
- gpu-buffer-size.txt
- buffer-sizes-linux-intel.txt
- buffer-sizes-radv-linux.txt
- buffer-sizes-windows-amd.txt
- buffer-sizes-windows-nvidia.txt
So, in practice, on these particular platforms, buffers do not appear to have such a wide range of storage and alignment requirements.
Assumptions
By combining some of the measurements we've seen so far, and by seeing what guarantees the Vulkan spec gives us, we can try to put together a set of assumptions that might help in putting together a system for allocating memory that can satisfy all the fairly painful requirements Vulkan demands.
Firstly, I believe that allocations for textures should be treated separately from allocations for buffers.
For textures: On the platforms we surveyed, textures have alignment requirements that fall within the integer powers of two in the range [2⁸, 2¹⁶]. We could therefore divide the heap into allocations based on alignment size and memory type. On the platforms we surveyed, this would effectively avoid creating too many allocations, because there were at most three different alignment values on a given platform.
When a texture is required that has an alignment size S
and memory type T, we sub-allocate from an existing allocation that has
been created for alignment size S and memory type T, or create a new one
if either the existing allocations are full, or no allocations exist. Within
an allocation, we can track blocks of size S. By working in terms of blocks
of size S, we guarantee that sub-allocations always have the correct
alignment. Additionally, by fixing S on a per-allocation basis, we reduce
wasted space: There will be no occurrences of small, unaligned sub-allocations
breaking up contiguous free space and preventing larger aligned sub-allocations
from being created.
We could choose to also group allocations by texture size, so allocations would
be created for a combination of alignment size S, memory type T, and texture
size P. I think this would likely be a bad idea unless the application only
used a single texture size; in applications that used a wide range of texture
sizes this would result in a large number of different allocations being created,
and it's possible the allocation count limit could be reached.
In terms of sizing the allocations used for textures, we can simplify the
situation further if we are willing to limit the maximum size of textures that
the application will accept. We can see from the existing data that a 4096x4096
texture using four bytes per pixel will require just over 64mb of storage space.
Many existing GPUs are capable of using textures at sizes of 8192x8192 and
above. We could make the simplifying assumption that any textures over, say,
2048x2048 are classed as humongous and would therefore use a different
allocation scheme. The Java virtual machine takes a
similar approach for objects
that have a size that is over a certain percentage of the heap size.
If we had an 8gb heap and divided it up into 32mb allocations, we could cover
the entire heap in around 250 allocations, and each allocation would be able
to store a 2048x2048 texture with room to spare. The same heap divided into 128mb
allocations would need just over 62 allocations to cover the entire heap. A
128mb allocation would easily hold at least one 4096x4096 texture. However,
the larger the individual allocations, the more likely it is that the entirety
of the heap could be used up before allocations could be created for all the
required combinations of S and T. We can derive a rough heuristic for
the allocation size for a heap of size H where the maximum allowed size for
a resource is M:
∃d. H / d ≃ K, size = max(M, d)
That is, there's some allocation size d that will divide the heap into roughly
K parts. The maximum allowed size of a resource is M. Therefore, the size
used for allocations should be whichever of d or M is larger. If we choose
K = 62 and are satisfied with resources that are at most 64mb, then
size = max(M, d) = max(64000000, 133333333) = 133333333.
We could simplify matters further by requiring that the application provide
up-front hints as to the range of texture sizes and formats that it is going
to use (and the ways in which those textures are going to be used). This would
be an impossibly onerous restriction for a general-purpose malloc(), but it's
perfectly feasible for a typical rendering engine.
This would allow us to evaluate the memory requirements of all the combinations
of S and T that are likely to be encountered when the application runs,
and try to arrange for an optimal set of allocations of sizes suitable for the
system's heap size. Obviously, the ideal situation for this kind of allocator would
be that the application would use exactly one size of texture, and would use
those textures in exactly one way. This is rarely the case for real
applications!
Within an allocation, we would take care to sub-allocate blocks using a
best-fit algorithm in order to reduce fragmentation. Most best-fit
algorithms run in O(N) time over the set of free spaces, but the size of
this set can be kept small by merging adjacent free spaces when deallocating
sub-allocations.
For humongous textures, the situation is slightly unclear. Unless the application is routinely texturing all of its models with massive images, then those humongous textures are likely to be render targets. If they aren't render targets, then the application likely has bigger problems! I suspect that the right thing to do in this case is to simply reject the allocation and tell the user "if you want to allocate a render target, then use this specific API for doing so". The render target textures can then be created as dedicated allocations and won't interfere with the rest of the texture memory allocation scheme.
For buffers: The situation appears to be much simpler. On all platforms
surveyed, the alignment restrictions for buffers fall within a small range
of small powers of two, and don't appear to change based on the buffer parameters
at all. We can use the same kind of S and T based bucketing scheme, but
be happy in the knowledge that all of our created allocations will probably
have the same S value.
Next Steps
I'm going to start work on a Java API to try to codify all of the above. Ideally there would be an API to examine the current platform and suggest reasonable allocation defaults, and a separate API to actually manage the heap(s) according to the chosen values. The first API would work along the lines of "here's the size of my heap, here are the texture sizes and formats I'm going to use; give me what you think are sensible allocation sizes".
There'll also need to be some introspection tools to measure properties such as contiguous space usage, fragmentation, etc.
Compaction and defragmentation is a topic I've not covered. It doesn't really seem like there's much to it other than "take all allocations and then sort all sub-allocations by size to free up space at the ends of allocations". It's slightly harder to actually implement because there will be existing Vulkan resources referring to memory that will have "moved" after defragmentation. The difficulty is really just a matter of designing a safe API around it.