In a crippling bout of sinusitis, and after reading that Chrome is going to mark http sites as insecure, I decided to put good sense aside and deploy Let's Encrypt certificates on the io7m servers.
I've complained about the complexity of this before, so I started thinking about how to reduce the number of moving parts, and the number of protection boundary violations implied by the average ACME setup.
I decided the following invariants must hold:
-
The web server must not have write access to its own configuration, certificates, or logs. This is generally a given in any server setup. Logging is actually achieved by piping log messages to a log program such as svlogd which is running as a different user. In my case, I can actually go much further and state that the web server must not have write access to anything in the filesystem. This means that if the web server is compromised (by a buffer overflow in the TLS library, for example), it's not possible for an attacker to write to any data or code without first having to find a way to escalate privileges.
-
The web server must have read access to a challenge directory. This is the directory containing files created in response to a Let's Encrypt (LE) challenge.
-
The
acmeclient must have read and write access to the certificates, and it must have write access to a challenge directory, but nothing else in the filesystem. Specifically, the client must not have write access to the LE account key or the directory that the web server is serving. This means that if the client is compromised, it can corrupt or reissue certificates but it can't substitute its own account key and request certificates on behalf of someone else. -
The
acmeclient must not have any kind of administrative access to the web server. I don't want theacmeclient helpfully restarting the web server because it thinks it's time to do so.
There are some contradictions here: The acme client must not be able to
write to the directory that the web server is serving, and yet the web
server must be able to serve challenge responses to the LE server. The
acme client must not be able to restart the web server, and yet the web
server must be restarted in order to pick up new certificates when they're
issued.
I came up with the following:
-
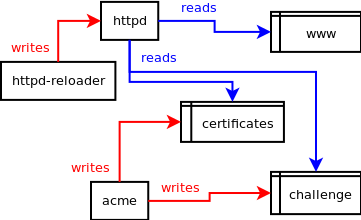
An
httpd-reloaderservice sends aSIGHUPsignal to the web server every 30 minutes. This causes the web server to re-read its own configuration data and reload certificates, but does not kill any requests that are in the process of being served and specifically does not actually restart the web server. -
The
acmeclient writes to a privatechallengedirectory, and a privatecertificatesdirectory. It doesn't know anything about the web server and is prevented from accessing anything other than those directories via a combination of access controls andchrooting. -
The web server reads from a read-only nullfs mount of a
wwwdatadirectory, and thechallengedirectory above is placed inwwwdata/.well-known/acme-challengevia another read-onlynullfsmount. The web server also reads from a read-onlynullfsmount of thecertificatesdirectory above in order to access the certificates that theacmeclient creates. -
The
acmeclient is told to update certificates hourly, but theacmeclient itself decides if it's really necessary to update the certificates each time (based on the time remaining before the certificates expire). -
The intrusion detection system has to be told that the web server's certificates are permitted to change. The account key is never permitted to change. I don't want notifications every ~90 days telling me the certificates have been modified.
I set up all of the above and also took some time to harden the
configuration by enabling various HTTP headers such as Strict-Transport-Security,
Content-Security-Policy, Referrer-Policy, etc. I'm not going to require
https to read io7m.com and I'm not going to automatically redirect
traffic from the http site to the https site. As far as I'm concerned,
it's up to the people reading the site to decide whether or not they want
https. There are plenty of browser addons that can tell the browser to
try https first, and I imagine Chrome is already doing this without
addons.
The Qualys SSL Labs result:
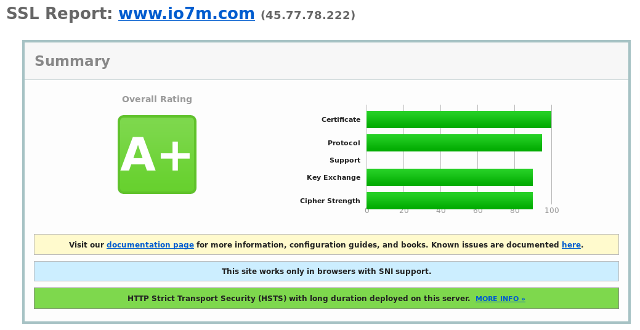
Now we can all sleep soundly in the knowledge that a third party that we
have no reason whatsoever to trust is telling us that io7m.com is safe.
I'm going to start making all projects use a common set of Checkstyle rules rather than having each project carry its own rules around. I can't remember exactly why I avoided doing this in the beginning. I think it may've been that I wasn't confident that I could write one set of rules that would work everywhere. I've decided instead that I'll beat code with a shovel until it follows the rules, rather than beat the rules with a shovel until they follow the code.
I've been moving all of the projects I still maintain to Java 9
modules. In order
to do this, however, I've needed to assist third party projects upon
which I have dependencies to either modularize their projects or
publish Automatic-Module-Name entries in their jar manifests. If
you try to specify a dependency on a project that either hasn't been
modularized or hasn't published an Automatic-Module-Name entry,
you'll see this when building with Maven:
[WARNING] ******************************************************************************************************************** [WARNING] * Required filename-based automodules detected. Please don't publish this project to a public artifact repository! * [WARNING] ********************************************************************************************************************
The reasons for this are documented on Stephen Colebourne's blog.
Here's a table of all of the third party projects upon which I depend, and an indication of the current state of modularization (I'll try to keep this updated as projects are updated):
| Project | State | Updated |
|---|---|---|
| fastutil | Considering | 2018-02-07 |
| jcpp | Considering | 2018-02-08 |
| ed25519-java | Considering | 2018-02-09 |
| LWJGL | Fully Modularized | 2018-02-07 |
| Dyn4j | Fully Modularized | 2018-02-07 |
| protobuf | Ignored? | 2018-02-07 |
| antlr | In Progress | 2018-02-11 |
| autovalue | In Progress | 2018-02-07 |
| rome | In Progress | 2018-02-07 |
| JGraphT | Automatic Module Names (Full modularization in progress) | 2018-02-11 |
| Vavr | Automatic Module Names | 2018-02-07 |
| commonmark-java | Automatic Module Names | 2018-02-07 |
| javapoet | Automatic Module Names | 2018-02-07 |
| xom | Unclear | 2018-02-07 |
Generally, if a project isn't planning to either modularize or publish automatic module names, then I'm looking for a replacement for that project.
I'm having trouble deploying packages to Maven Central. The repository claims that it cannot validate the signatures I provide. I've filed a bug but haven't gotten a response. I'm wondering if it's down to me switching to Curve25519 PGP keys...
New PGP keys have been published.
Fingerprint | UID ----------------------------------------------------------------------------------- B84E 1774 7616 C617 4C68 D5E5 5C1A 7B71 2812 CC05 | Mark Raynsford (2018 personal) F8C3 C5B8 C86A 95F7 42B9 36D2 97E0 2011 0410 DFAF | io7m.com (2018 release-signing)