
In a recent post to the bndtools-users mailing list, I
expressed a bit of frustration with my experience of trying out
Bndtools for what I think must be about
the fourth time. Jürgen Albert had mentioned on the osgi-dev
list that he had a working environment where, every time he
clicked "Save" in his IDE, bundles would automatically be built
and deployed to a running OSGi container.
This gave him effectively live updates to running code during development. I'd still not
been able to achieve this in my Maven
and IDEA environment,
so I took another look at Bndtools to see if it could be
done. Any OSGi user will be familiar with being able to deploy
new parts of a running system without having to restart it, but
actually being able to instantly deploy code every time you change
as little as a single line of code is probably not something that
every OSGi user has access to.
On the bndtools-users list, Raymond Auge mentioned to me that he'd
recently added functionality to an as-yet-unreleased version of the
bnd-run-maven-plugin
that might be able to solve the problem. It worked beautifully!
Using the following setup, it's possible to get live code updates
without having to stray outside of a traditional Maven setup; your
build gets to remain a conventional Maven build and, if you don't
use the feature, you probably don't have to know the plugin exists
at all.
The setup described here assumes a multi-module Maven project. I describe it in these terms because all of my projects are multi-module, and it should be trivial to infer, for anyone familiar with Maven, the simpler single-module setup given the more complex multi-module setup.
A complete, working example project is available on GitHub. The example project contains:
com.io7m.bndtest.api: A simple API specification for hello world programs.com.io7m.bndtest.vanilla: An implementation of thecom.io7m.bndtest.apispec.com.io7m.bndtest.main: A consumer of thecom.io7m.bndtest.apispec; it looks up an implementation and uses it.com.io7m.bndtest.run: Administrative information for setting up an OSGi runtime.
At the time of writing, the version of the bnd-run-maven-plugin
you need is currently only available as a development snapshot.
Add the following pluginRepository to the root POM of your
Maven project:
<pluginRepositories>
<pluginRepository>
<id>bnd-snapshots</id>
<url>https://bndtools.jfrog.io/bndtools/libs-snapshot/</url>
<layout>default</layout>
<releases>
<enabled>false</enabled>
</releases>
</pluginRepository>
</pluginRepositories>
This will no longer be necessary once version 4.3.0 is officially
released.
Add an execution of this plugin in the root POM of your project:
<build>
<plugins>
...
<plugin>
<groupId>biz.aQute.bnd</groupId>
<artifactId>bnd-run-maven-plugin</artifactId>
<version>4.3.0-SNAPSHOT</version>
</plugin>
</plugins>
</build>
Add a module to your project (in the example code, this is com.io7m.bndtest.run) that will be used to declare
the information and dependencies required to start a basic
OSGi runtime. In this case, I use Felix
and install a minimal set of services such as a Gogo shell and Declarative Services.
These aren't necessary for the plugin to function, but the example
code on GitHub uses Declarative Services, and the Gogo shell makes
it easier to poke around in the OSGi runtime to see what's going on.
The POM file for this module should contain dependencies for all of the bundles you wish to install into the OSGi runtime, and all the OSGi framework and services. In my case this looks like:
<dependencies>
<dependency>
<groupId>${project.groupId}</groupId>
<artifactId>com.io7m.bndtest.api</artifactId>
<version>${project.version}</version>
</dependency>
<dependency>
<groupId>${project.groupId}</groupId>
<artifactId>com.io7m.bndtest.vanilla</artifactId>
<version>${project.version}</version>
</dependency>
<dependency>
<groupId>${project.groupId}</groupId>
<artifactId>com.io7m.bndtest.main</artifactId>
<version>${project.version}</version>
</dependency>
<dependency>
<groupId>org.apache.felix</groupId>
<artifactId>org.apache.felix.framework</artifactId>
</dependency>
<dependency>
<groupId>org.apache.felix</groupId>
<artifactId>org.apache.felix.gogo.shell</artifactId>
</dependency>
<dependency>
<groupId>org.apache.felix</groupId>
<artifactId>org.apache.felix.gogo.command</artifactId>
</dependency>
<dependency>
<groupId>org.apache.felix</groupId>
<artifactId>org.apache.felix.shell.remote</artifactId>
</dependency>
<dependency>
<groupId>org.apache.felix</groupId>
<artifactId>org.apache.felix.shell</artifactId>
</dependency>
<dependency>
<groupId>org.apache.felix</groupId>
<artifactId>org.apache.felix.scr</artifactId>
</dependency>
<dependency>
<groupId>org.apache.felix</groupId>
<artifactId>org.apache.felix.log</artifactId>
</dependency>
<dependency>
<groupId>org.osgi</groupId>
<artifactId>osgi.promise</artifactId>
</dependency>
</dependencies>
A single execution of the bnd-run-maven-plugin is needed in this
module, along with a simple bndrun file. Note that the name of the
plugin exection must be unique across the entire set
of modules in the Maven reactor. You will be referring to this name
later on the command line, so pick a sensible name (we use main
here). Note that the name of the bndrun file can be completely
arbitrary; the name of the file does not have to be in any way
related to the name of the plugin execution.
<build>
<plugins>
<plugin>
<groupId>biz.aQute.bnd</groupId>
<artifactId>bnd-run-maven-plugin</artifactId>
<executions>
<execution>
<id>main</id>
<configuration>
<bndrun>main.bndrun</bndrun>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
The main.bndrun file is unsurprising to anyone with a passing
familiarity with bnd. We specify that we want Felix to be the
OSGi framework, and we list the set of bundles that should be
installed and executed. We don't bother to specify version numbers
because this information is already present in the Maven POM.
$ cat main.bndrun -runfw: \ org.apache.felix.framework -runee: JavaSE-11 -runrequires: \ osgi.identity;filter:='(osgi.identity=com.io7m.bndtest.main)' -runbundles: \ com.io7m.bndtest.api, \ com.io7m.bndtest.main, \ com.io7m.bndtest.vanilla, \ org.apache.felix.gogo.command, \ org.apache.felix.gogo.runtime, \ org.apache.felix.gogo.shell, \ org.apache.felix.log, \ org.apache.felix.scr, \ org.apache.felix.shell, \ org.apache.felix.shell.remote, \ osgi.promise, \
Now that all of this is configured, it's necessary to do a
full Maven build and execute the plugin. Note that, due to
a Maven limitation, it is necessary to call the bnd-run-maven-plugin
in the same operation as the package lifecycle. In other
words, execute this:
$ mvn package bnd-run:run@main
The @main suffix to the run command refers to the named main
execution we declared earlier. The above command will run a Maven
build and then start an OSGi instance and keep it in the foreground:
$ mvn package bnd-run:run@main
[INFO] Scanning for projects...
[INFO] ------------------------------------------------------------------------
[INFO] Reactor Build Order:
[INFO]
[INFO] com.io7m.bndtest [pom]
[INFO] com.io7m.bndtest.api [jar]
[INFO] com.io7m.bndtest.vanilla [jar]
[INFO] com.io7m.bndtest.main [jar]
[INFO] com.io7m.bndtest.run [jar]
...
[INFO] ---------------< com.io7m.bndtest:com.io7m.bndtest.run >----------------
[INFO] Building com.io7m.bndtest.run 0.0.1-SNAPSHOT [5/5]
[INFO] --------------------------------[ jar ]---------------------------------
[INFO]
...
[INFO] --- bnd-run-maven-plugin:4.3.0-SNAPSHOT:run (main) @ com.io7m.bndtest.run ---
____________________________
Welcome to Apache Felix Gogo
g! lb
START LEVEL 1
ID|State |Level|Name
0|Active | 0|System Bundle (6.0.3)|6.0.3
1|Active | 1|com.io7m.bndtest.api 0.0.1-SNAPSHOT - Bnd experiment (API) (0.0.1.201905160844)|0.0.1.201905160844
2|Active | 1|com.io7m.bndtest.main 0.0.1-SNAPSHOT - Bnd experiment (Main consumer) (0.0.1.201905160845)|0.0.1.201905160845
3|Active | 1|com.io7m.bndtest.vanilla 0.0.1-SNAPSHOT - Bnd experiment (Vanilla implementation) (0.0.1.201905160845)|0.0.1.201905160845
4|Active | 1|Apache Felix Gogo Command (1.1.0)|1.1.0
5|Active | 1|Apache Felix Gogo Runtime (1.1.2)|1.1.2
6|Active | 1|Apache Felix Gogo Shell (1.1.2)|1.1.2
7|Active | 1|Apache Felix Log Service (1.2.0)|1.2.0
8|Active | 1|Apache Felix Declarative Services (2.1.16)|2.1.16
9|Active | 1|Apache Felix Shell Service (1.4.3)|1.4.3
10|Active | 1|Apache Felix Remote Shell (1.2.0)|1.2.0
11|Active | 1|org.osgi:osgi.promise (7.0.1.201810101357)|7.0.1.201810101357
At this point, there is a running OSGi container in the foreground.
The bnd-run-maven-plugin is monitoring the jar files that were created
as part of the Maven build and, if those jar files are changed, the plugin will
notify the framework that it's necessary to reload the code.
Now, given that we want to make rebuilding and updating running code as quick as possible, we almost certainly don't want to have to do a full Maven build every time we change a line of code. Luckily, we can configure IDEA to do the absolute minimum amount of work necessary to achieve this.
First, open the Run Configurations window:
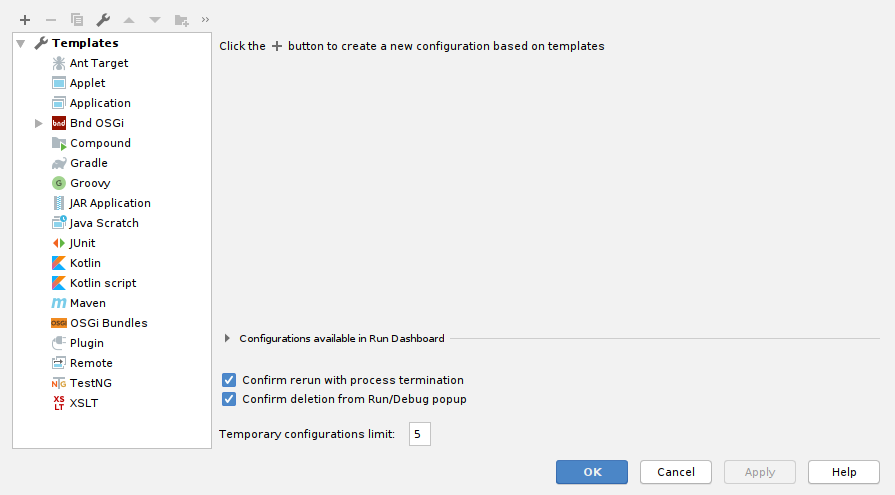
Add a Maven build configuration:
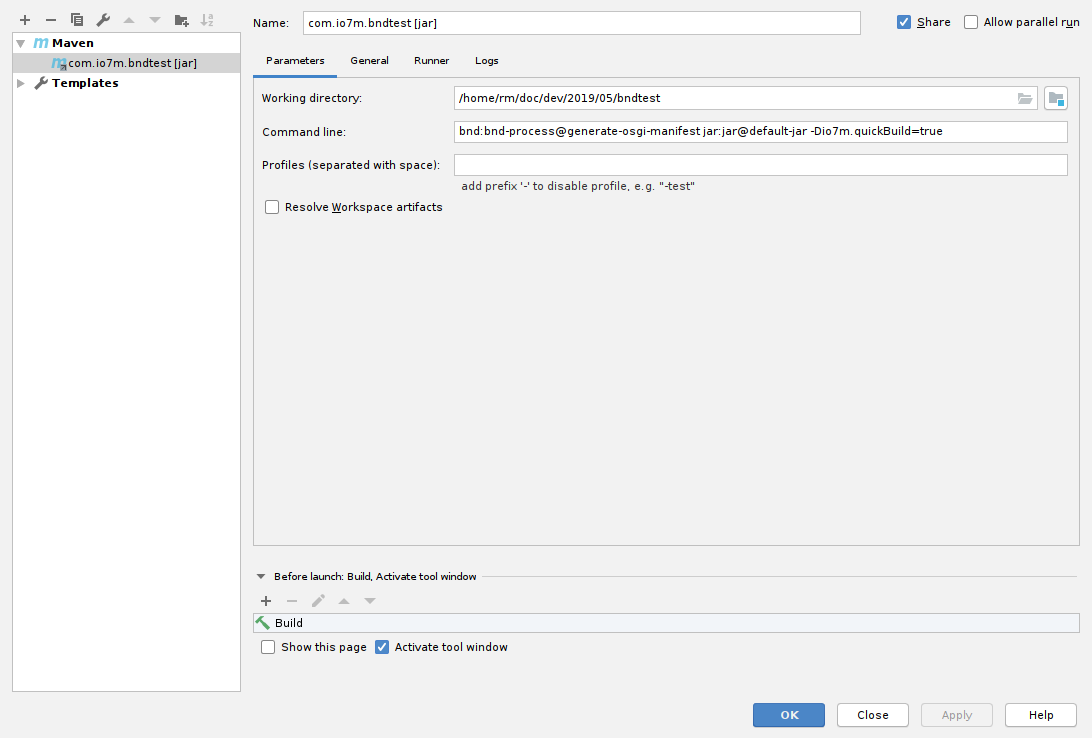
The precise Maven command-line used will depend on your
project setup. In the example code, I have an execution of the
bnd-maven-plugin named generate-osgi-manifest that does the work
necessary to create an OSGi manifest. I also have an execution of the
maven-jar-plugin named default-jar that adds the generated manifest
to the created jar file. I also declare a property io7m.quickBuild
which turns off any plugin executions that aren't strictly necessary
during development. All of these things are configurations declared
in the primogenitor
parent POM that I use for all projects, but none of them should
be in any way unfamiliar to anyone that has put together a basic
bnd-maven-plugin-based project. The gist is: Tell Maven to run
the bnd-maven-plugin and generate an OSGi manifest for each module,
and then tell it to create a jar for each module.
The other important item is to add a Before Launch option (at the bottom of the window) that runs a normal IDE build before Maven is executed. The reason for this is speed: We want the IDE to very quickly rebuild class files (this is essentially instant on my system), and then we want to execute the absolute bare minimum in terms of Maven goals after the IDE build.
One small nit here: The root module of your project will almost certainly
have a packaging of type pom instead of type jar. The bnd-maven-plugin
will (correctly) skip the creation of a manifest file for this module, and
this will then typically cause the maven-jar-plugin to complain that there
is no manifest file to be inserted into the jar that it's creating. A quick
and dirty workaround is to do this in the root of the project:
mkdir -p target/classes/META-INF touch target/classes/META-INF/MANIFEST.MF
In the example project, I include a small run.sh script that actually does
this as part of starting up the OSGi container:
#!/bin/sh mkdir -p target/classes/META-INF touch target/classes/META-INF/MANIFEST.MF exec mvn package bnd-run:run@main
I strongly recommend not doing this as part of the actual Maven build itself; this is something that's only needed by developers who are making use of this live code updating setup during development, and isn't something that the Maven build needs to know about. By executing specific plugins, we're not calling Maven in the way that it would normally be called and therefore it's up to us to ensure that things are set up correctly so that the plugins can work.
With both of these things configured, we should now be able to click Run
in IDEA, and the code will be built in a matter of seconds:
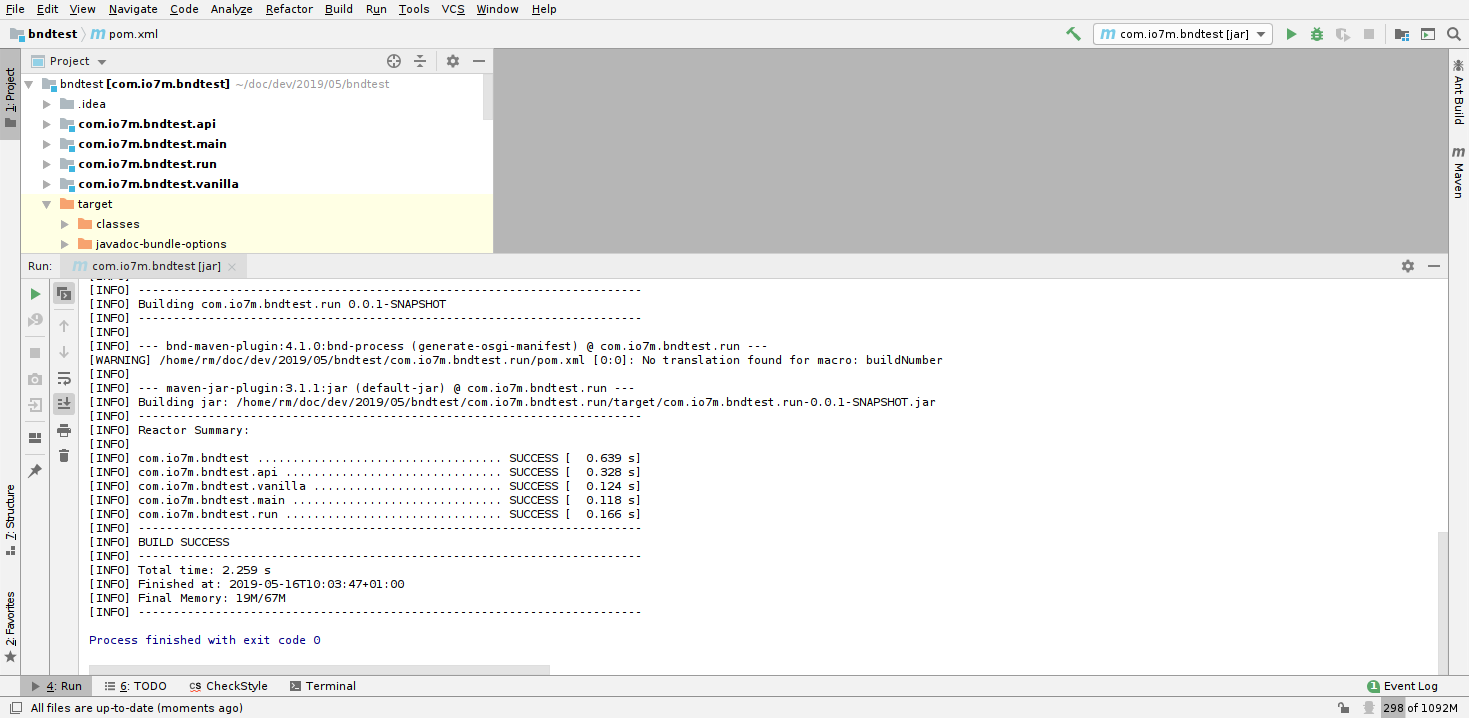
Assuming that our OSGi container is still running somewhere, the rebuilt jar files will be detected and the code will be reloaded automatically:
[INFO] Detected change to /home/rm/doc/dev/2019/05/bndtest/com.io7m.bndtest.api/target/com.io7m.bndtest.api-0.0.1-SNAPSHOT.jar. Reloading. Speak: onDeactivate Speak: onActivate Speak: Hello again, again!
Once again, OSGi demonstrates how unique it currently is: I don't know of any other system that provides a type-safe, version-safe, dynamic update system such as this. I know of other systems that do it dangerously, or in a type-unsafe way, or without the benefits of strong API versioning, but none that do things as safely and correctly as OSGi.
In the past couple of years, I've gotten back into composing music after a fifteen year break. I had originally stopped making music without any expectation that I'd ever do it again. Making music had become extremely stressful due to two factors: economics, and proprietary software. Briefly, I'd assumed that I needed to make money from music because I believed I had no other skills. This lead to a very fear-driven and unpleasant composition process more suited to producing periodic mild mental breakdowns than listenable music. Additionally, all of the software I was using to make music was the standard vendor lock-in proprietary fare; That's a nice studio you have here, it'd be a shame if you stopped paying thousands of monetary units per year to keep it working exactly the same way it always has and something happened to it... What? You want to use some different software and migrate your existing data to it? Ha ha ha! You're not going anywhere!
So I gave up and got into software instead. Fast forward fifteen years and now, as a (presumably) successful self-employed software engineer and IT consultant, economics are no longer a factor. Additionally, after fifteen years of using, contributing to, developing, and publishing open-source software, coupled with huge advances in the quality of all of the available open-source music software - I no longer have any desire or use for proprietary audio software. There is nothing that any proprietary audio software vendor can offer me that I could conceivably want.
As I mentioned, my music composition process in the distant past had been very fear-driven, and I'd accumulated a ton of rather destructive mental habits. However, fifteen years of meditation and other somewhat occult practices have left with me the tools needed to recognize, identify, and extinguish those mental habits.
One habit that I identified very early turned out to be one that was common amongst other musicians I know. Specifically: Too much detail too soon. In essence, it's very easy in modern electronic music composition environments to write four bars of music (looping the music continuously as you write), and progressively add more and more detail to the music, and do more and more tuning and adjustments to the sounds. Before long, eight hours have passed and you have four very impressive bars of music, and no idea whatsoever as to what the next four bars are going to be. Worse, you've essentially induced a mild hypnotic trance by listening to the same section of music over and over, and have unconsciously cemented the idea into your mind that these four bars of music are going to be immediately followed by the same four bars. Even worse; you've almost certainly introduced a set of very expensive (in terms of computing resources here, but perhaps in terms of monetary cost too, if you're that way inclined) electronic instruments and effects in an attempt to get the sound just the way you like it, and you may now find that it's practically impossible to write any more music because the amount of electronic rigging has become unwieldy. If you're especially unlucky, you may have run out of computing resources. Better hope you can write the rest of the music using only those instrument and plugin instances you already have, because you're not going to be creating any more!
Once I'd identified this habit, I looked at ways to eliminate it before it could manifest. I wanted to ensure that I'd written the entirety of the music of the piece before I did any work whatsoever on sounds or production values. The first attempt at this involved painstakingly writing out a physical score in MuseScore using only the built-in general MIDI instruments. The plan was to then take the score and recontextualize it using electronic instruments, effects, et cetera. In other words, the composition would be explicitly broken up into stages: Write the music, use the completed music as raw MIDI input to a production environment, and then manipulate the audio, add effects, and so on to produce a piece that someone might actually want to listen to. As an added bonus, I'd presumably come away with a strong understanding of the music-theoretic underpinnings of the resulting piece, and I'd also be forced into making the actual music itself interesting because I'd not be able to rely on using exciting sounds to maintain my own interest during the composition process.
The result was successful, but I'd not try it again; having to write out a score using a user interface that continually enforces well-formed notation is far too time consuming and makes it too difficult to experiment with instrument lines that have unusual timing. MuseScore is an excellent program for transcribing music, but it's an extremely painful and slow environment for composition. In defense of MuseScore: I don't think it's really intended for composition.
Subsequent attempts to compose involved writing music in a plain MIDI sequencer on a piano roll, but using only a limited number of FM synth instances. Dexed, specifically. These attempts were mostly successful, but I still felt a tendency to play with and adjust the sounds of the synthesizers as I wrote. The problem was that the sounds that Dexed produced were actually good enough to be used as the final result, and I was specifically trying to avoid doing anything that could be used as a final result at this stage of the composition.
So, back to the drawing board again. I reasoned that the problem was down to using sounds that could conceivably appear in the final recording and, quite frankly, being allowed any control whatsoever over the sounds. An obvious solution presented itself: Write the music using the worst General MIDI sound module you can find. Naming no names, I found a freely-available SoundFontⓡ that sounded exactly like a low-budget early 90s sound module. Naturally, I could never publish music that used a General MIDI sound module with a straight face. This would ensure that I wrote all the music first without any possibility of spending any time playing with sounds and then (and only then) could I move to re-recording the finished music in an environment that had sounds that I could actually tolerate.
Attempts to compose music in this manner were again successful, but it became apparent that General MIDI was a problem. The issue is that General MIDI sound modules attempt to (for the most part) emulate actual physical acoustic instruments. This means that if you're presented with the sound of a flute, you'll almost certainly end up writing monophonic musical lines that could conceivably be played on a flute. The choice of instrument sound inevitably influences the kind of musical lines that you'll write.
What I wanted were sounds that:
-
Sounded bad. This ensures that the sounds chosen during the writing of the music won't be the sounds that are used in the final released version of the piece.
-
Sounded different to each other. A musician who's opinion I respect suggested that I use pure sine waves. The problem with this approach is that once you have four or five sine wave voices working in counterpoint, it becomes extremely hard to work out which voice is which. I need sounds that are functionally interchangeable and yet are recognizably distinct.
-
Sounded abstract. I don't want to have any idea what instrument the sound is supposed to represent. It's better if it doesn't represent any particular instrument; I don't want to be unconsciously guided to writing xylophone-like or brass-like musical lines just because the sound I randomly pick sounds like a xylophone or trumpet.
-
Required little or no computing resources. I want to be able to have lots of instruments without being in any way concerned about computing resource use. Additionally, I don't want to deal with any synthesizer implementation bugs during composition.
Reviewing all the options, I decided that the best way to achieve the above would be to produce a custom SoundFontⓡ. There are multiple open source implementations available that can play SoundFontⓡ files, and all of them are light on resource requirements and appear to lack bugs. I wanted a font that contained a large range of essentially unrecognizable sounds, all of which could be sustained indefinitely whilst a note is held. There were no existing tools for the automated production of SoundFontⓡ files, so I set to work:
-
jsamplebuffer provides a simple Java API to make it easier to work with buffers of audio samples.
-
jnoisetype provides a Java API and command-line tools to read and write SoundFontⓡ files.
I then went through hundreds of Dexed presets collected from freely-available
DX7 patch banks online, and collected 96 sounds that were appropriately
different from each other. I put together some Ardour
project files used to export the sounds from Dexed instances into FLAC
files that could be sliced up programatically and inserted into a SoundFontⓡ
file for use in implementations such as FluidSynth.
The result: Unbolted Frontiers.
A SoundFontⓡ that no sensible person could ever want to use. 96 instruments using substandard 22khz audio samples, each possessing the sole positive quality that they don't sound much like any of the others. Every note is overlaid with a pure sine wave to assist with the fact that FM synthesis tends to lead to sounds that have louder sideband frequencies than they do fundamental frequencies. All instruments achieve sustain with a simple crossfade loop. Hopefully, none of the instruments sound much like any known acoustic instrument. The only percussion sounds available sound like someone playing a TR-808 loudly and badly.
If I hear these sounds used in recorded music, I'm going to be very disappointed.
It's that time of year again.
-----BEGIN PGP SIGNED MESSAGE----- Hash: SHA512 Fingerprint | Comment - ------------------------------------------------------------------------ E379 5957 1613 1DB4 E7AB 87DD 67B1 8CC1 F9AC E345 | 2019 maven-rsa-key D345 CCB7 187B C973 BDD4 9192 BEC8 33E4 DCAA 5330 | 2019 android commit signing DD3E 9631 2A83 748C B4B3 73A5 91A8 14E2 EAF7 50A3 | 2019 release-signing 33E7 E23B F949 E558 A333 38E3 562B F636 4C42 DA2E | 2019 maven-rsa-key -----BEGIN PGP SIGNATURE----- iHUEARYKAB0WIQTjeVlXFhMdtOerh91nsYzB+azjRQUCXCuhgwAKCRBnsYzB+azj ReAKAQCdag7RQljpNSdNZKe6Yd59cWsyk2N3dPZzyj1epjdVlgD/aqzs13xoKkJn uycYrtoIXLbo2cEFmPleL0/CI8f4gA8= =1ziK -----END PGP SIGNATURE-----
Keys are published to the keyservers as usual.
I do a bit of 3D rendering now and then using Blender. Blender has multiple rendering engines: Blender Internal and Cycles. Blender Internal is a 1990s style CPU-based raytracer, and Cycles is a physically-based renderer that can be executed on either CPUs or GPUs. Cycles is technologically superior to Blender Internal in every way except for one: The performance when running on CPUs is essentially hopeless. In order to get reasonable render times, you really need a powerful GPU with an appropriate level of driver support. I refuse to use proprietary hardware drivers for both practical reasons and reasons of principle. This has meant that, to date, I haven't been able to use Cycles with GPU acceleration and have therefore stuck to using Blender Internal. As I don't aim for photorealism in anything I render (I prefer a sort of obviously-rendered pseudo-impressionist style), Blender Internal has been mostly sufficient.
However, I've recently moved to rendering 1080p video at 60fps. This means that even if it only takes ~10 seconds to render a single frame, that's still about 35 hours of rendering time to produce a 3.5 minute video.
I have a few machines around the place here that spend a fair amount
of time mostly idle. I decided to look for ways to distribute rendering
tasks across machines to use up the idle CPU time. The first thing I
looked at was netrender.
Unfortunately, netrender is both broken and abandonware. I spent
a good few hours spinning up VM instances and trying to get it to
work, but it didn't happen.
I've been using Jenkins for a while now to build and test code from hundreds of repositories that I maintain. I decided to see if it could be useful here... After a day or so of experimentation, it turns out that it makes an acceptable driver for a render farm!
I created a set of nodes used for rendering tasks. A node in
Jenkins speak is an agent program running on a computer that accepts
commands such as "check out this code now", "build this code now",
etc. I won't bother to go into detail on this, as setting up nodes
is something anyone with any Jenkins experience already knows how
to do. Nodes can be assigned labels so that tasks can be assigned
to specific machines. For example, you could add a linux label to
machines running Linux, and then if you had software that would only
build on Linux, you could set that job to only run on nodes that
are labelled with linux. Basically, I created one node for each
idle machine here and labelled them all with a blender label to
distinguish them from the nodes I use to build code.
I then placed my Blender project and all of the required assets into a Git repository.
I created a new job in Jenkins that checks out the git repository above and runs the following pipeline definition included in the repository:
#!groovy
// Required: https://plugins.jenkins.io/pipeline-utility-steps
node {
def nodes = nodesByLabel label:"blender"
def nodesSorted = nodes.sort().toList()
def nodeTasks = [:]
def nodeCount = nodesSorted.size()
for (int i = 0; i < nodeCount; ++i) {
def nodeName = nodesSorted[i]
def thisNodeIndex = i
nodeTasks[nodeName] = {
node(nodeName) {
stage(nodeName) {
checkout scm
sh "./render.sh ${thisNodeIndex} ${nodeCount}"
}
}
}
}
parallel nodeTasks
}
This uses the pipeline-utility-steps
plugin to fetch a list of online nodes with a particular label from Jenkins. I make
the simplifying assumption that all online nodes with the blender label will be
participating in render tasks. I assign each node a number, and I create a new task
that will run on each node that runs a render.sh shell script from the repository.
The tasks are executed in parallel and the job is completed once all subtasks have
run to completion.
The render.sh shell script is responsible for executing Blender.
Blender has a full command-line interface for rendering images without opening
a user interface. The main command line parameters we're interested in are:
blender \
--background \
coldplanet_lofi.blend \
--scene Scene \
--render-output "${OUTPUT}/########.png" \
--render-format PNG \
--frame-start "${NODE_INDEX}" \
--frame-end "${FRAME_COUNT}" \
--frame-jump "${NODE_COUNT}" \
--render-anim
The --frame-start parameter indicates at which frame the node should start
rendering. The --frame-end parameter indicates the last frame to render. The
--frame-jump parameter indicates the number of frames to step forward each
time. We pass in the node index (starting at 0) as the starting frame,
and the number of nodes that are participating in rendering as the frame
jump. Let's say there are 4 nodes rendering: Node 0 will start at
frame 0, and will then render frame 4, then frame 8, and so on. Node
1 will start at frame 1, then render frame 5, and so on. This means
that the work will be divided up equally between the nodes. There are
no data dependencies between frames, so the work parallelizes easily.
When Jenkins is instructed to run the job, all of the machines pull the git repository and start rendering. At the end of the task, they upload all of their rendered frames to a server here in order to be stitched together into a video using ffmpeg. Initial results seem promising. I'm rendering with three nodes, and rendering times are roughly 30% of what they were with just the one node. I can't really ask for more than that.
There are some weaknesses to this approach:
-
Rendering can't be easily resumed if the job is stopped. This could possibly be mitigated by building more intelligence into the
render.shfile, but maybe not. -
Work is divided up equally, but nodes are not equal. I initially tried adding a node to the pool of nodes that was much slower than the others. It was assigned the same amount of work as the other nodes, but took far longer to finish. As a result, the work actually took longer than it would have if that node hadn't been involved at all. In fact, in the initial tests, it took longer than rendering on a single node!
-
There's not really a pleasant way to estimate how much longer rendering is going to take. It's pretty hard to read the console output from each machine in the Jenkins UI.
Finally: All of this work is probably going to be irrelevant very soon. Blender 2.8 has a new realtime rendering engine - EEVEE - which should presumably mean that rendering 3.5 minutes of video will take me 3.5 minutes.